Underwater cave exploration and visual mapping are crucial for our understanding of archaeology, hydro-geology, and water resource management.
While manual cave surveys are labor-intensive and hazardous operations, the use of Autonomous Underwater Vehicles (AUVs) has been limited as well.
The major challenges lie in visual scene parsing and safe navigation inside underwater caves in the complete absence of ambient light.
In this project, we present CaveSeg - the first visual learning pipeline for semantic segmentation and
scene parsing for AUV navigation inside underwater caves. We address the problem of scarce annotated data by preparing a comprehensive
dataset for semantic segmentation of underwater cave scenes. It contains pixel annotations for important navigation markers (e.g. caveline, arrows),
obstacles (e.g. ground plane and overhead layers), scuba divers, and open areas for servoing. Through comprehensive benchmark analyses on cave
systems in USA, Mexico, and Spain locations, we demonstrate that robust deep visual models can be developed based on CaveSeg for fast semantic scene
parsing of underwater cave environments.
In particular, we formulate a novel transformer-based model that is computationally light and offers near
real-time execution in addition to achieving state-of-the-art performance. We explore the design choices and implications of semantic
segmentation for visual servoing by AUVs inside underwater caves.
The first figure shows an ROV deployment scenario inside the Orange Grove Cave System in Florida. Perspective (a) is captured by a human diver following the ROV from behind;
(b) is the corresponding POV from the robot’s camera;
and the proposed semantic parsing concept is shown in (c).
Furthermore, we highlight several challenging scenarios and practical use cases of CaveSeg for real-time AUV navigation inside underwater caves.
Those scenarios include safe cave exploration by caveline following and obstacle avoidance, planning towards caveline rediscovery, finding safe open
passages and exit directions inside caves, giving uninterrupted right-of-way to scuba divers exiting the cave, and 3D semantic mapping and state estimation.
We demonstrate that CaveSeg-generated semantic labels can be utilized effectively for vision-based cave exploration and semantic mapping by AUVs.
The following video summarizes the detailed contributions and provides a rough outline of this project.
Dataset Preparation
CaveSeg is the first large-scale semantic segmentation dataset for underwater cave exploration. We collect comprehensive training data by ROVs and scuba divers through
robotics trials in three major locations: the Devil’s system in Florida, USA; Dos Ojos Cenote in QR, Mexico; and
Cueva del Agua in Murcia, Spain. Please refer to the Caveline project page for more details on the locations.
Our processed data contain 3350 pixel-annotated samples with 13 object categories. We also compile
a CaveSeg-Challenge test set that contains 350 samples from unseen waterbody and cave systems such as the Blue Grotto and Orange Grove cave systems in FL, USA.
The 13 object categories are: caveline, first layer (immediate avoidance areas), second layer (areas to be avoided subsequently), open area
(obstacle-free regions), ground plane, scuba divers, caveline-attached rocks, and navigation aids (arrows, reels, and cookies). Moreover, stalactites, stalagmites,
and columns are also considered if they are present in the scene, which is the case for the Mexico caves. The following figure shows a few sample images and
corresponding label overlay. Navigation aids are also separately shown on the right.
The dataset is available here.
CaveSeg Learning Pipeline
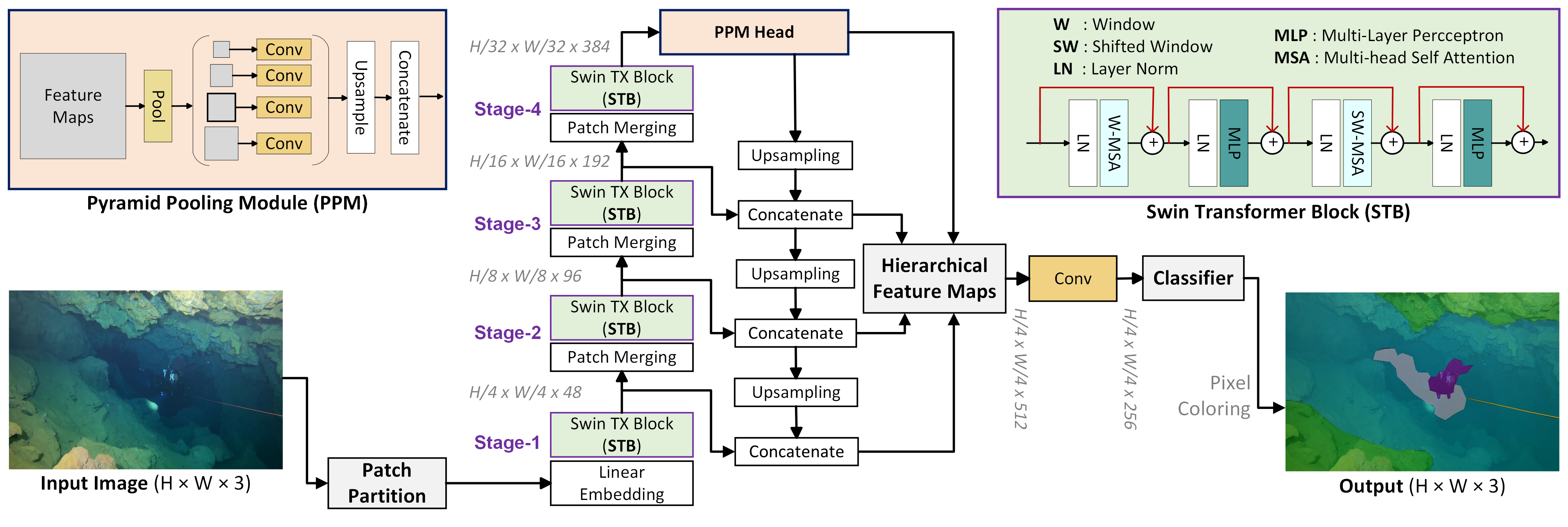
We develop a novel CaveSeg model by rigorous design choices to balance the robustness-efficiency trade-off.
The proposed model consists of a transformer-based backbone, a multi-scale pyramid pooling head, and a hierarchical
feature aggregation module for robust semantic learning.
The detailed network architecture is shown in the following figure. First, input RGB images are partitioned into 4 × 4 non-overlapping
patches or tokens; a linear embedding layer of dimension 48 is then applied to each token. These feature
tokens are passed through a four-stage backbone, each containing a windowed and shifted windowed module of multi-head self-attention.
In each stage, patches are merged with 2 × 2 neighboring regions to reduce the number of tokens while at the same time,
the linear embedded dimension is doubled. Subsequently, bottom-up and top-down feature
aggregation is performed in two separate branches. A pyramid pooling module (PPM) is attached to the backbone that further
improves global feature extraction at deep layers of the network. Features from each stage of the
backbone as well as from the PPM head are then fused and compiled into a hierarchical feature map. Finally, a fully
connected convolution layer performs pixel-wise category estimation on that feature space.
Segmentation Performance
Qualitative performance.
The following figure compares the qualitative performance of CaveSeg with four top-performing SOTA models (detailed results are in the paper).
A unique feature of CaveSeg and
other transformer-based models is that they perform better in finding large and connected areas, e.g., categories such as
first/second layer obstacles and open areas. The continuous regions segmented by the CaveSeg model facilitate a better
understanding of the surroundings compared to DeepLabV3+ and FastFCN. This validates our intuition that window-shifting
technique can indeed extract global features more accurately. While the shifted window method focuses on
global feature extraction, the deeper layers and multi-scale pooling of PPM help to preserve the details of local features.
The precise detection of caveline, which is only a few pixels wide, further supports this design choice.
Quantitative performance.
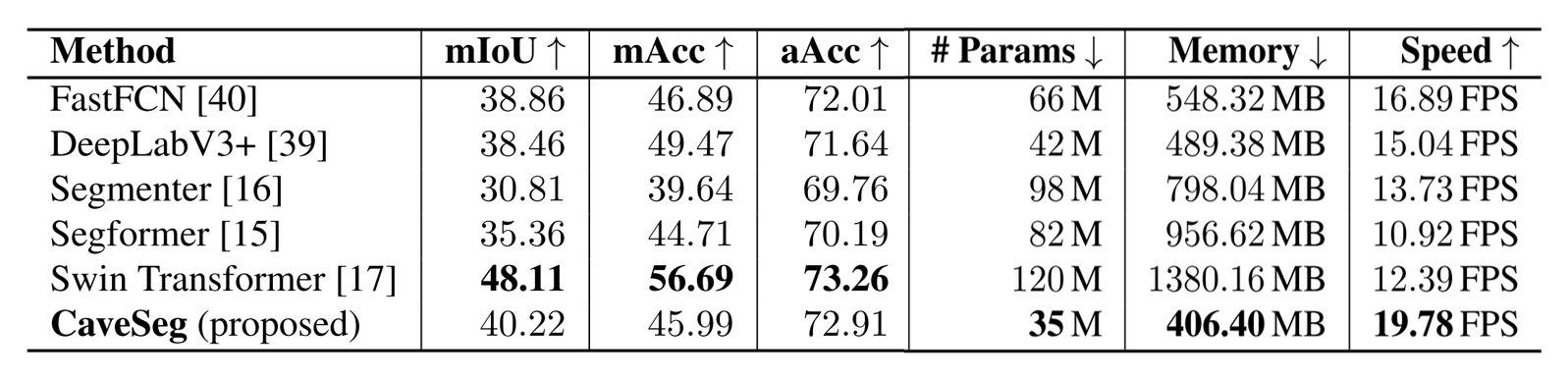
Our proposed dataset and learning pipelines can achieve up to 68% accuracy for pixel-wise seg-
mentation. The proposed CaveSeg model offers comparable performance margins despite having a significantly lighter
architecture. The comparison metrics are provided in the following table. CaveSeg model has less than 50% parameters
than other competitive models and offers up to 1.8× faster inference rates. While we analyze the class-wise
performance, we find that small and rare object categories such as arrows, cookies, and reels are challenging in general.
Practical Application
The confined nature of the underwater cave environment makes obstacle avoidance a particularly important
task. A few challenging scenarios are shown in the adjacent figure.
In the first scenario, simply following the caveline
is not sufficient due to the cluttered scene geometry. With the semantic knowledge of first layer and second layer
obstacles, and open areas - an AUV can plan its trajectory safely and efficiently. In the second image, no open area is visible but an arrow is
pointing toward the nearest exit. In case of navigation failure, the AUV can follow the arrows and the caveline to safely exit the cave. Another important category is
the scuba divers.
Additionally, an AUV should always give the right of way to divers, especially those exiting the cave.
In case of an emergency, there should be nothing impeding the divers from reaching the surface, which is a norm practiced by cave divers.
As such, CaveSeg maintains a label for divers to
ensure appropriate actions by the AUV upon detection of a diver. Specifically, in the presence of a diver, the lights of the vehicle will be dimmed
so that the approaching diver can see the caveline. The AUV will reduce its speed, and refrain from using the
downward-facing propellers to avoid stirring up the sediment; see Figure (a) below. Finally, the vehicle will move away from the caveline towards the walls of the cave.
Moreover, safe navigation approaches, such as AquaNav and AquaVis can generate smooth paths by avoiding obstacles.
To this end, having a holistic semantic map of the scene can ensure that the AUV can safely follow the caveline and keep it in
the FOV during cave exploration. Our CL-ViT work demonstrates the utility of caveline detection and following for autonomous underwater cave exploration.
While caveline detection is paramount, having semantic knowledge about the surrounding objects in the scene is essential to ensure safe AUV navigation.
As shown in Figure (b) below, cavelines can be obscure in particular areas due to occlusions and blends inside the cave passages. Hence, dense semantic information provided by CaveSeg is important to ensure continuous tracking and re-discovery of the caveline and other navigation markers.
Another prominent use case of CaveSeg is the 3D estimation and reconstruction of caveline for AUV navigation.
Specifically, 2D caveline estimation can be combined with camera pose estimation from Visual-Inertial-Odometry (VIO) to generate 3D estimates.
This could potentially be used to compare and improve manual surveys of existing caves. Moreover, 3D caveline estimations can also be utilized
to reduce uncertainty in VIO and SLAM systems since the line directions in 3D point clouds can provide additional spatial constraints.
We demonstrate a sample result; see Figure (c) above, where 'ray-plane triangulation' of cavelines is achieved using
Visual-Inertial pose estimation for enabling 3D perception capabilities for underwater cave exploration. This experiment is performed on field data
collected by ROVs in the Orange Grove cave system, FL, USA; we are currently exploring these capabilities for more comprehensive 3D semantic mapping of
underwater caves.
Acknowledgments
This research has been supported in part by the NSF grants 1943205 and $2024741.
The authors would also like to acknowledge the help from the Woodville Karst Plain Project (WKPP), El Centro Investigador del Sistema Acuífero de Quintana Roo A.C. (CINDAQ),
Global Underwater Explorers (GUE), Ricardo Constantino, and Project Baseline in collecting data and providing access to challenging underwater caves.
We also appreciate Evan Kornacki for coordinating our field trials. Lastly, we thank Richard Feng, Ailani Morales, and Boxiao Yu for their assistance
in collecting and annotating preliminary data in this project. The authors are also grateful for equipment support by Halcyon Dive Systems, Teledyne FLIR LLC, and KELDAN GmbH lights.