| Summer 2025 |
Robotics Reading Group Papers |
| 67 |
Information-Theoretic Generalization Bounds of Replay-based Continual Learning |
Highlights:
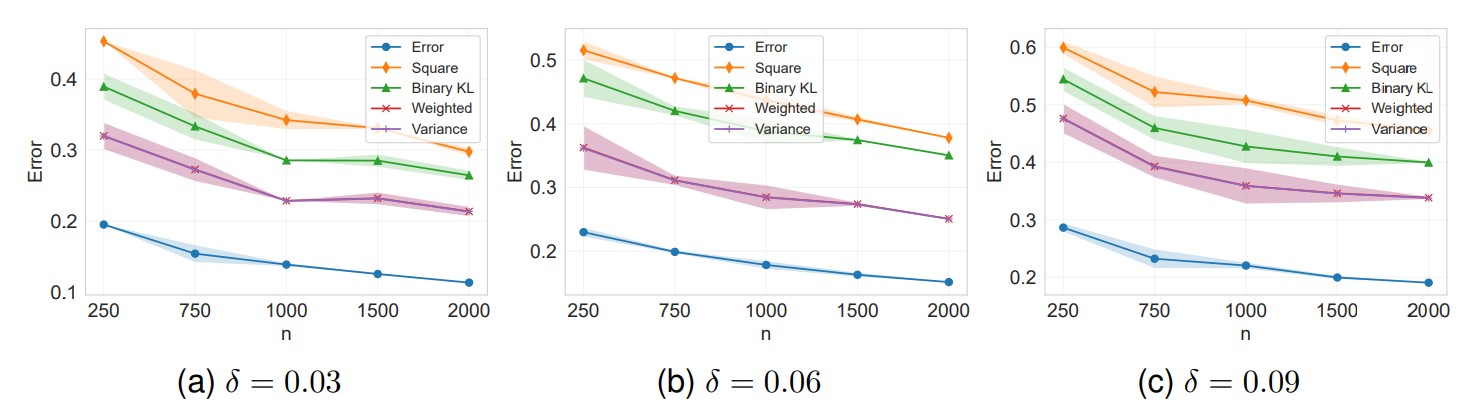
- Developed a unified theoretical framework for replay-based continual learning (CL), providing information-theoretic bounds that quantify how memory buffers influence generalization across sequential tasks.
- Showed that selectively using limited exemplars from previous tasks alongside current task data improves generalization and mitigates catastrophic forgetting, compared to exhaustive replay.
- Derived prediction-based bounds that are tighter and computationally tractable, applicable to a wide range of learning algorithms, including stochastic gradient Langevin dynamics (SGLD).
|
| 66 |
Opening the Black Box of Deep Neural Networks via Information |
Highlights:
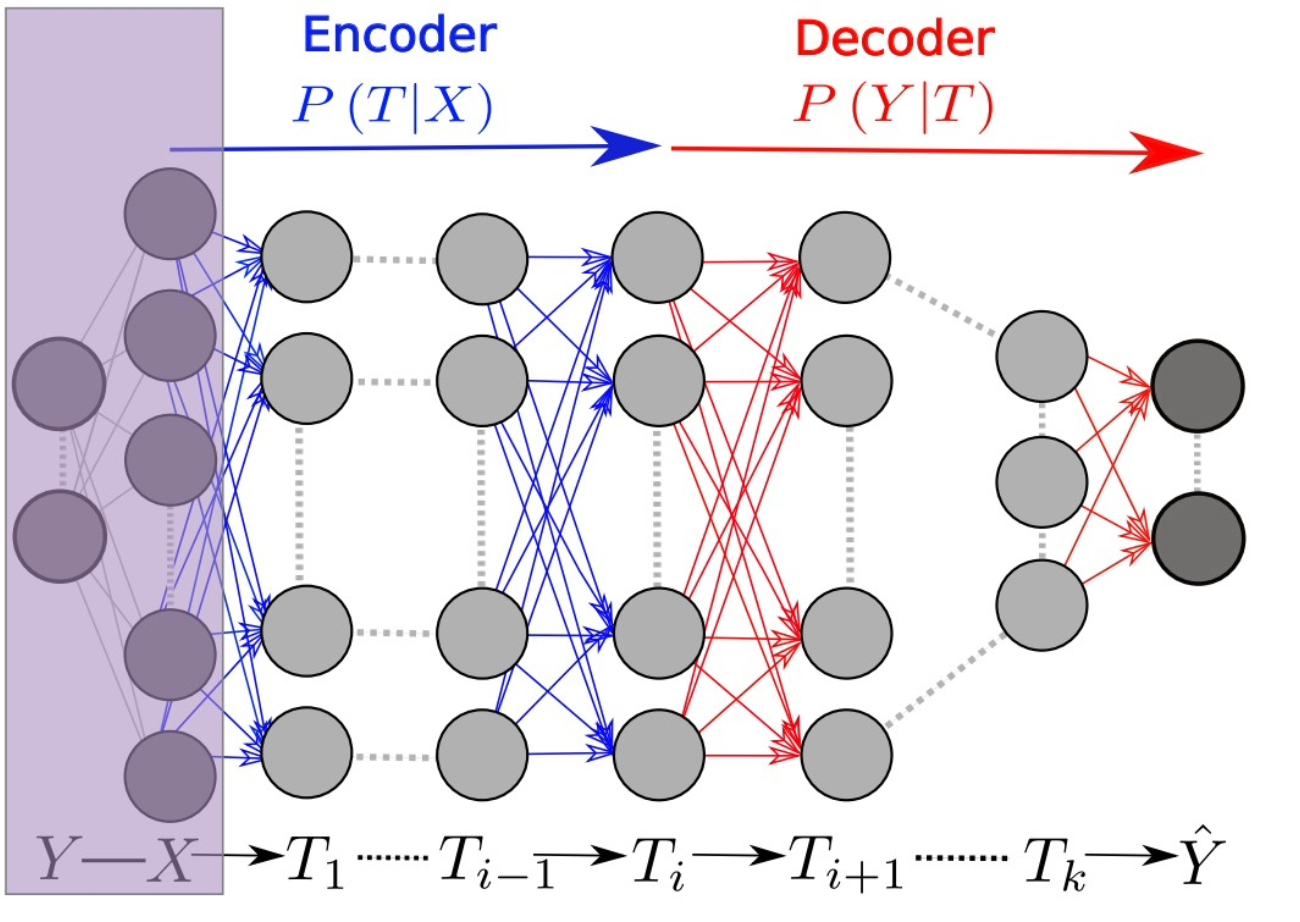
- Analyzed Deep Neural Networks (DNNs) using the Information Plane, showing that most training epochs are spent compressing input representations rather than fitting labels.
- Identified that compression begins when training error is low, with Stochastic Gradient Descent (SGD) transitioning from fast drift to stochastic relaxation, and that converged layers align closely with the Information Bottleneck (IB) theoretical bound.
- Demonstrated that adding hidden layers significantly reduces training time by accelerating the relaxation phase, highlighting a computational advantage of deep architectures.
|
| 65 |
MINE: Mutual Information Neural Estimation |
Highlights:
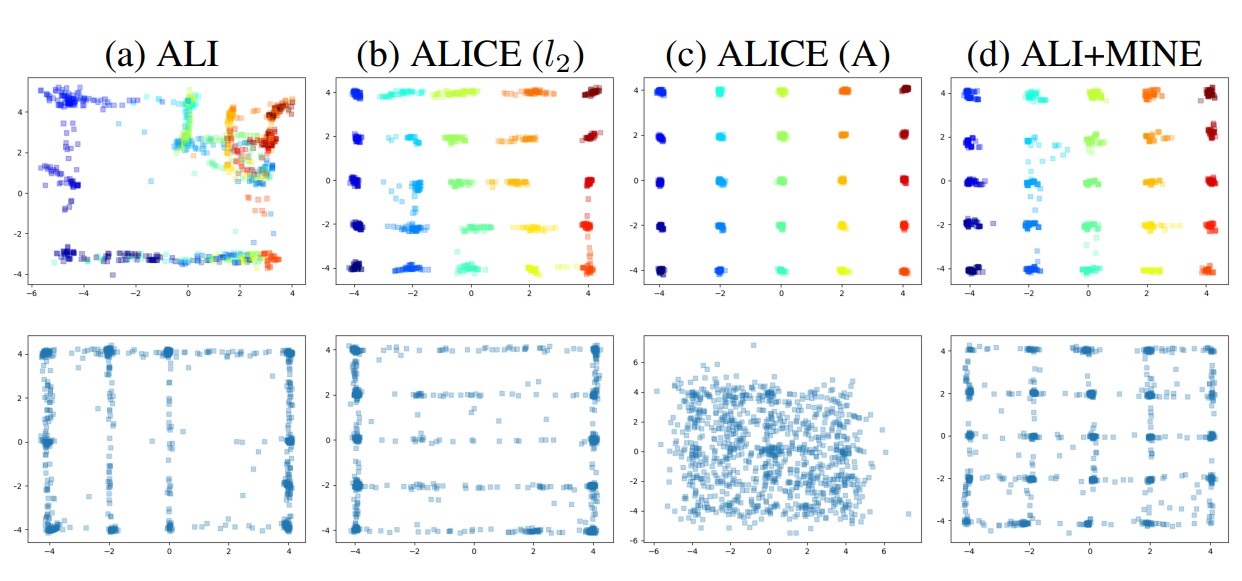
- Introduced the Mutual Information Neural Estimator (MINE), a scalable, backpropagation-trainable method for estimating mutual information between high-dimensional continuous variables.
- Demonstrated MINE’s applications in minimizing or maximizing mutual information, including enhancing adversarially trained generative models.
- Applied MINE to the Information Bottleneck framework for supervised classification, showing substantial improvements in flexibility and performance.
|
| 64 |
Toward 6-DOF Autonomous Underwater Vehicle Energy-Aware Position Control based on Deep Reinforcement Learning: Preliminary Results |

Highlights:
- Proposed a DRL-based control approach for holonomic 6-DOF AUVs using the Truncated Quantile Critics (TQC) algorithm, eliminating the need for manual tuning or prior knowledge of thruster configuration.
- Integrated power consumption into the reward function to optimize energy efficiency alongside maneuverability.
- Simulation results show the TQC High-Performance method outperforms fine-tuned PID controllers in goal-reaching tasks, while the TQC Energy-Aware method reduces power consumption by 30% with slightly lower performance.
|
| 63 |
Increase in Stability of an X-Configured AUV through Hydrodynamic Design Iterations with the Definition of a New Stability Index to Include Effect of Gravity |
Highlights:
- Presented a study on how different stationary and movable appendage configurations affect the dynamic stability of an AUV, introducing a new vertical-plane stability index that accounts for hydrostatic forces, even at low speeds.
- Applied the new stability index to various configurations of the DIVE AUV, using virtual planar motion mechanism (VPMM) and CFD simulations to evaluate hydrodynamic coefficients, straight-line maneuvers, and turn-circle trajectories.
- Concluded that hydrostatic restoring forces at low-to-moderate speeds and the design of control surfaces significantly influence control-fixed course stability of the AUV.
|
| 62 |
Thrust Allocation Control of an Underwater Vehicle with a Redundant Thruster Configuration |
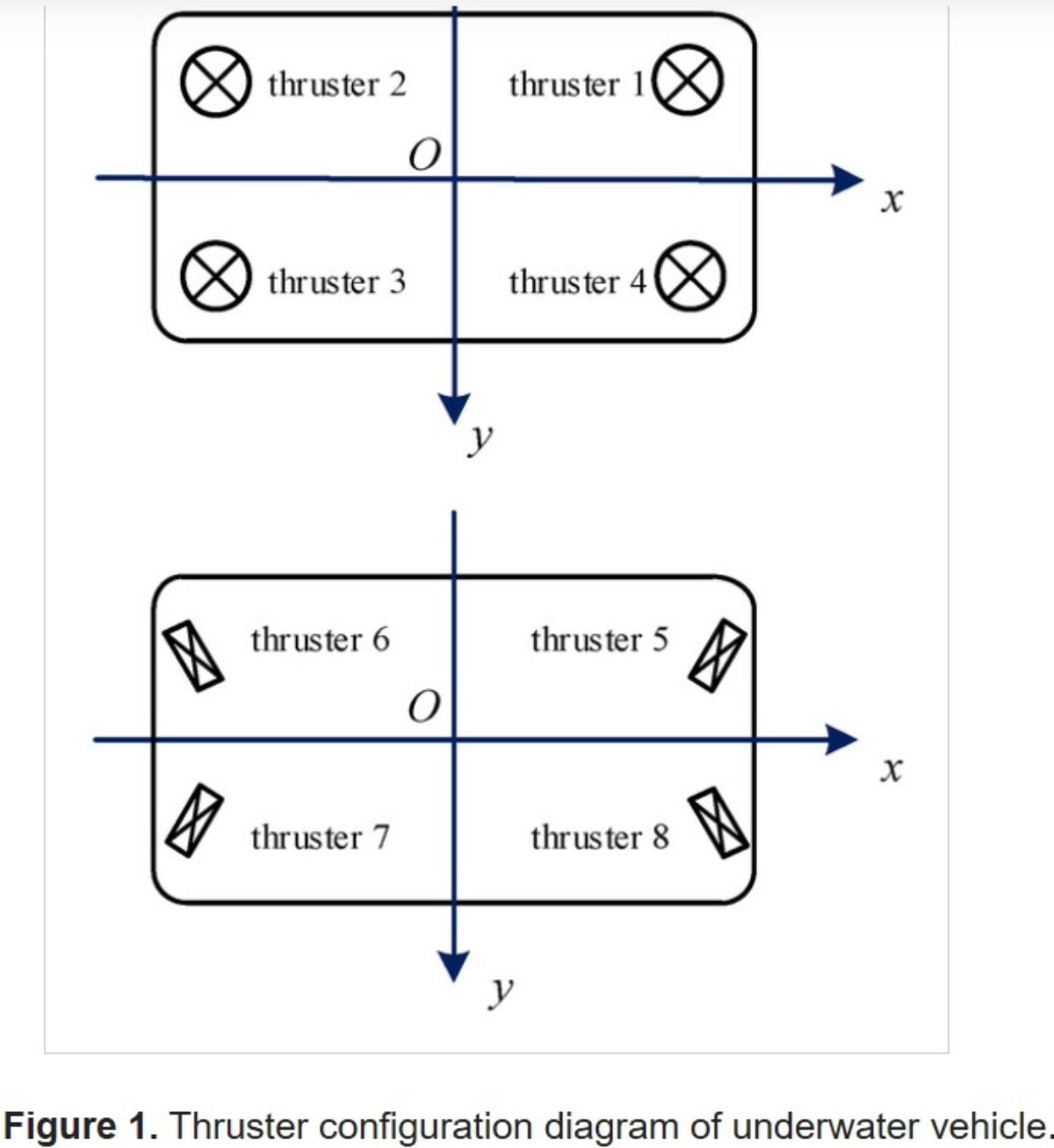
Highlights:
- Proposed a fault-tolerant 8-thruster vector configuration for underwater vehicles, analyzing the impact of thruster failures on 6-DOF maneuverability.
- Developed a mathematical model relating individual thruster outputs to virtual control forces and introduced a quadratic programming (QP)-based thrust allocation strategy to optimize energy efficiency while respecting thrust limits.
- Simulation results show strong fault tolerance and significantly improved energy savings compared to traditional least-squares-based thrust allocation methods.
|
| 61 |
Fast-DDPM: Fast Denoising Diffusion Probabilistic Models for Medical Image-to-Image Generation |
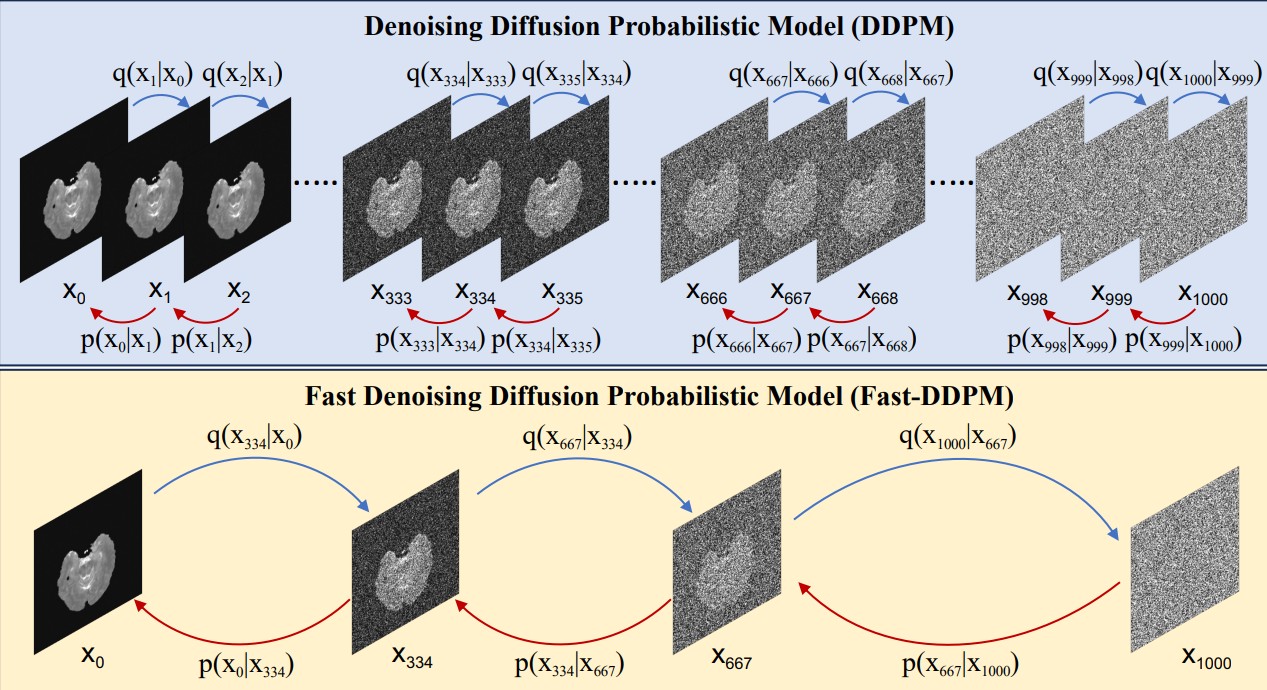
Highlights:
- Introduced Fast-DDPM, a diffusion-based approach for medical imaging that trains and samples using only 10 time steps, significantly reducing computational cost compared to standard DDPMs.
- Developed two efficient noise schedulers (uniform and non-uniform) to align training and sampling, improving generation quality, training speed, and sampling speed simultaneously.
- Evaluated on multi-image super-resolution, denoising, and image-to-image translation, outperforming DDPMs and state-of-the-art convolutional and GAN-based methods, while reducing training time to 20% and sampling time to 1% of standard DDPM.
|
| 60 |
DiffETM: Diffusion Process Enhanced Embedded Topic Model |
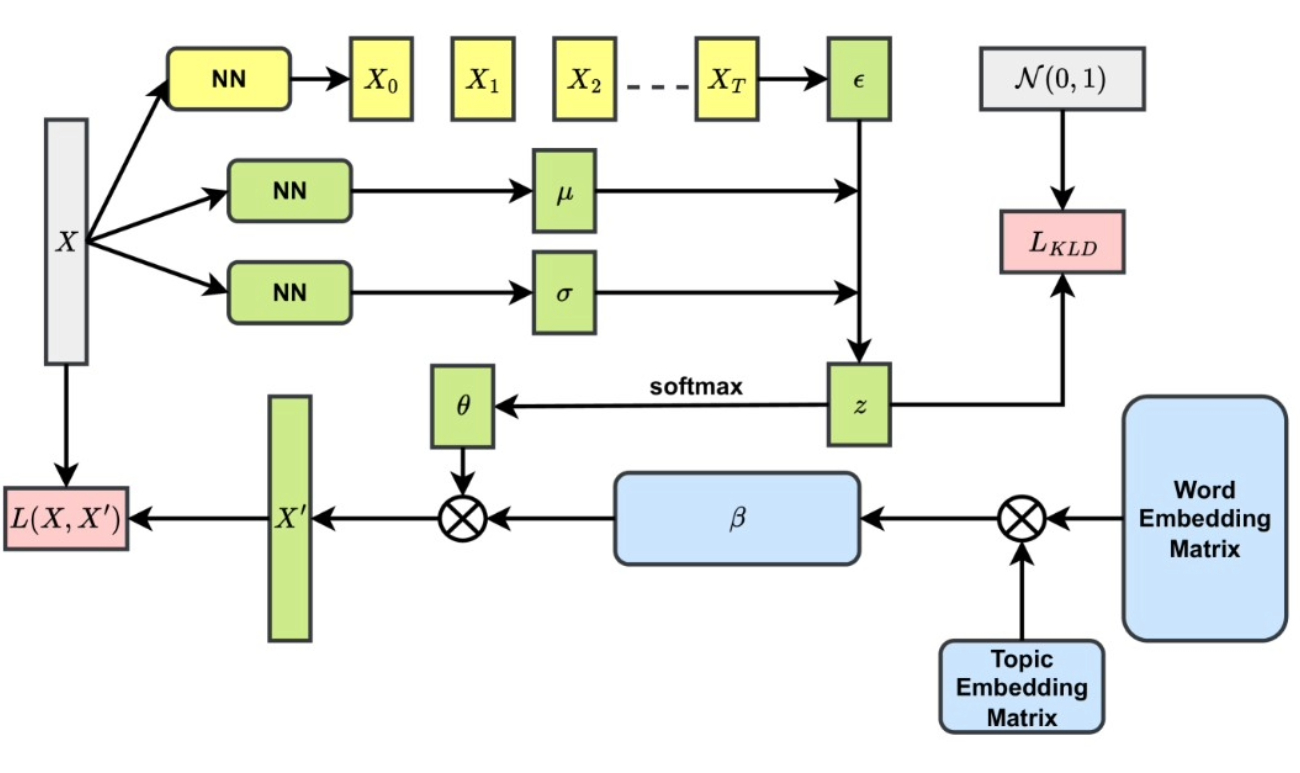
Highlights:
- Identified a limitation in Embedded Topic Models (ETM) where assuming a logistic normal distribution oversimplifies the true document-topic distribution.
- Proposed introducing a diffusion process into the sampling of document-topic distributions to better capture their complexity while retaining easy optimization.
- Validated the approach on two mainstream datasets, demonstrating improved topic modeling performance.
|
| 59 |
Atlantis: Enabling Underwater Depth Estimation with Stable Diffusion |

Highlights:
- Proposed a pipeline to generate photorealistic underwater images from terrestrial depth data using Stable Diffusion, enabling supervised training for underwater monocular depth estimation despite limited real-world data.
- Introduced Depth2Underwater ControlNet, trained on {Underwater, Depth, Text} triplets, to create diverse and realistic underwater scenes while preserving accurate depth information.
- Demonstrated that models trained on this dataset outperform terrestrial-pretrained counterparts on unseen underwater images and improve depth-guided underwater image restoration tasks.
|
| 58 |
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory |

Highlights:
- Proposed Marigold-DC, a depth completion method that treats the task as image-conditional depth map generation guided by sparse measurements, leveraging a pretrained latent diffusion model for monocular depth estimation.
- Integrates sparse depth observations at test time via an optimization scheme alongside iterative denoising diffusion inference, enabling robust handling of sparse, irregular, or varying-density depth inputs.
- Demonstrates strong zero-shot generalization across diverse environments, suggesting that using dense image priors guided by sparse depth is more effective than traditional sparse depth inpainting approaches.
|
| 57 |
Unsupervised Depth Completion from Visual Inertial Odometry |

Highlights:
- Proposed a method to infer dense depth from camera motion and sparse visual-inertial odometry points by constructing a piecewise planar scene scaffolding and leveraging images along with sparse points
- Employs a predictive cross-modal self-supervised criterion combining photometric consistency, forward-backward pose consistency, and geometric compatibility with sparse points.
- Introduced the first visual-inertial + depth dataset and demonstrated state-of-the-art performance on the unsupervised KITTI depth completion benchmark.
|
| 56 |
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory |
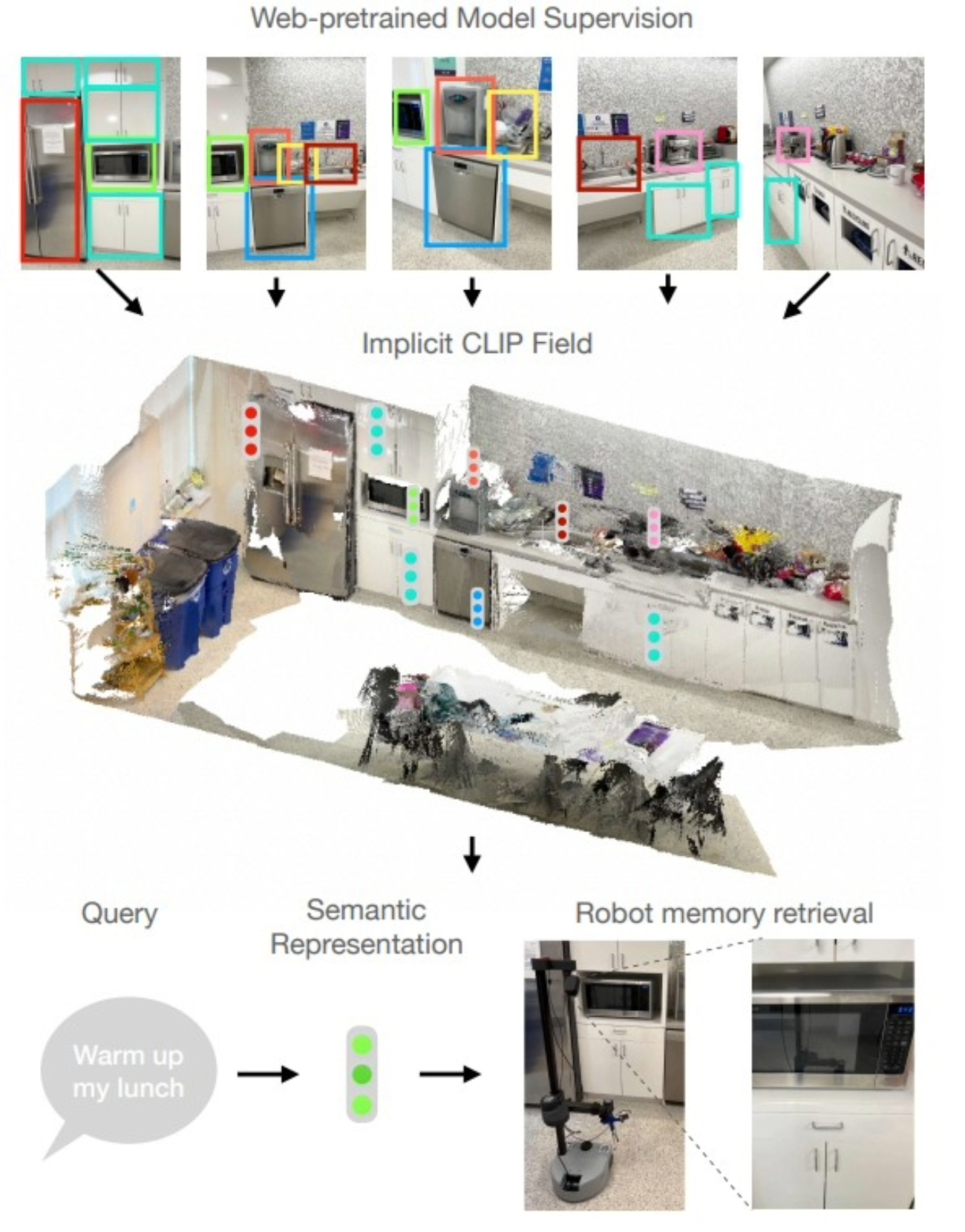
Highlights:
- Proposed CLIP-Fields, an implicit scene model that maps spatial locations to semantic embeddings for tasks like segmentation, instance identification, semantic search, and view localization.
- Trains using only supervision from pre-trained models (CLIP, Detic, Sentence-BERT) without direct human annotations, achieving superior few-shot performance on HM3D compared to baselines like Mask-RCNN.
- Demonstrated that CLIP-Fields can serve as a scene memory, enabling robots to perform semantic navigation in real-world environments.
|
| 55 |
CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision |
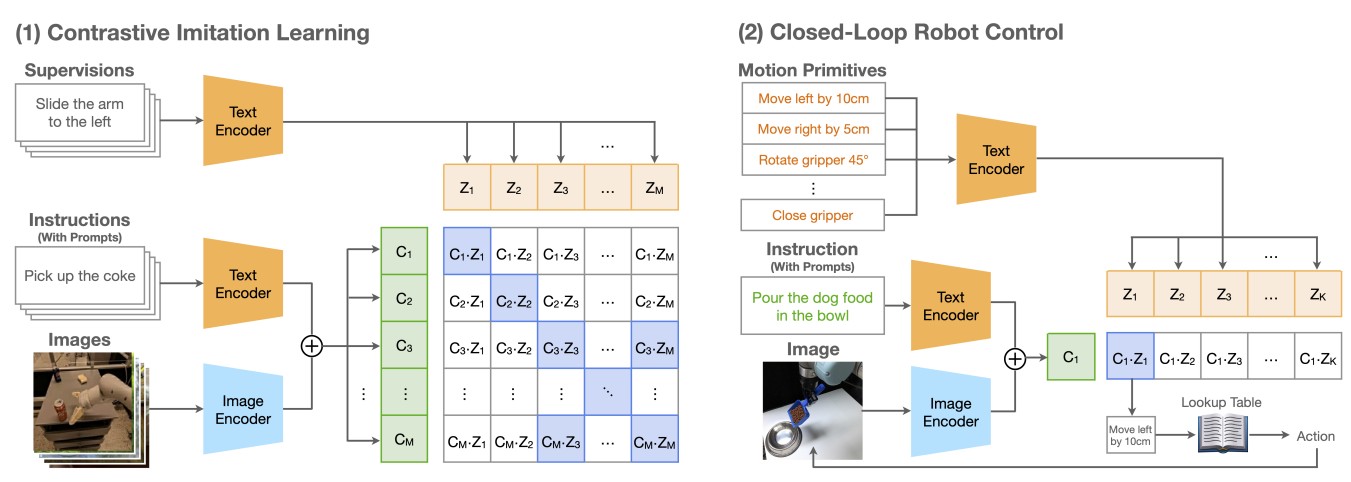
Highlights:
- Introduced a natural language-based data collection framework enabling non-experts to provide robot demonstrations and augment them for training.
- Developed CLIP-RT, a vision-language-action model that learns language-conditioned visuomotor policies via contrastive imitation learning, adapting CLIP to predict motion primitives.
- Evaluated on real-world and simulated tasks, CLIP-RT outperforms OpenVLA by 24% in success rates with 7× fewer parameters, generalizes in few-shot and collaborative scenarios, and achieves 93.1% success on the LIBERO benchmark at 163 Hz inference.
|
| 54 |
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation |
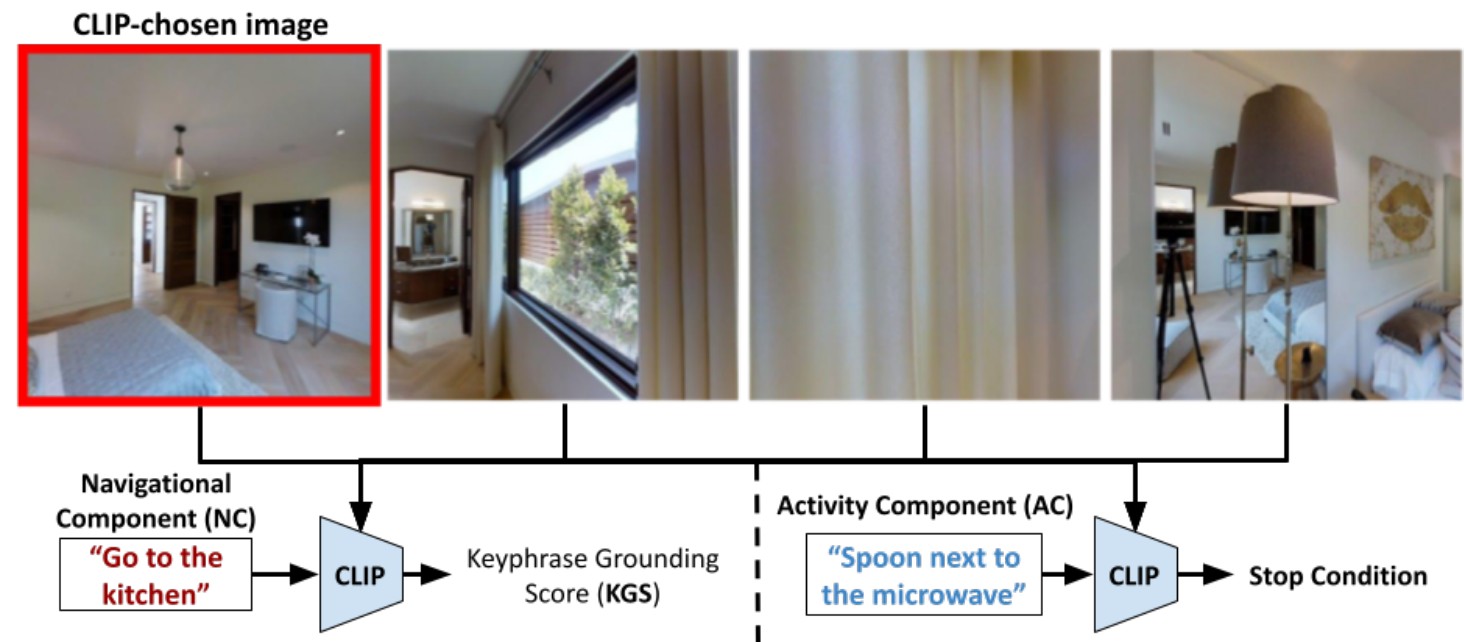
Highlights:
- Investigated zero-shot Vision-and-Language Navigation (VLN) using CLIP to ground natural language referring expressions without dataset-specific fine-tuning.
- Demonstrated that CLIP can guide sequential navigational decisions, outperforming supervised baselines on the REVERIE coarse-grained instruction following task in terms of success rate (SR) and success weighted by path length (SPL).
- Showed that the CLIP-based zero-shot approach generalizes better across environments, achieving more consistent performance than state-of-the-art fully supervised methods based on Relative Change in Success (RCS).
|
| 53 |
A Tale of Two Features: Stable Diffusion Complements DINO for Zero-Shot Semantic Correspondence |

Highlights:
- Explored the use of Stable Diffusion (SD) features for semantic and dense correspondence across multiple images, showing they perform comparably to state-of-the-art representations with simple post-processing.
- Found that SD features provide high-quality spatial information but less accurate semantic matches, complementing sparse but precise matches from DINOv2; fusing the two improves performance significantly.
- Demonstrated zero-shot evaluation on benchmark datasets (SPair-71k, PF-Pascal, TSS) and enabled applications such as instance swapping between images.
|
| 52 |
Exploring Semantic Feature Discrimination for Perceptual Image Super-Resolution and Opinion-Unaware No-Reference Image Quality Assessment |
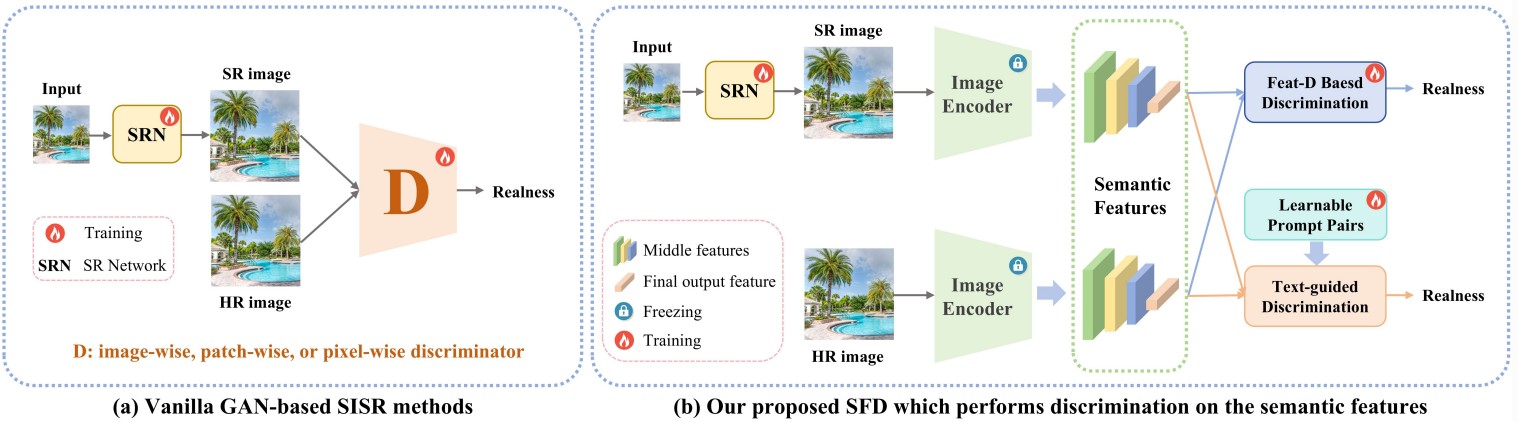
Highlights:
- Proposed Semantic Feature Discrimination (SFD) for perceptual image super-resolution, using a feature discriminator (FeatD) to align SR image features with high-quality image features from CLIP.
- Introduced text-guided discrimination (TG-D) with learnable prompt pairs (LPP) to enhance abstract feature discrimination, enabling the SR network to generate realistic, semantic-aware textures.
- Leveraged trained FeatD and LPP to develop SFD-IQA, an opinion-unaware no-reference image quality assessment method, achieving strong performance without additional targeted training.
|
| 51 |
Learning Generalizable Perceptual Representations for Data-Efficient No-Reference Image Quality Assessment |

Highlights:
- Proposed a no-reference (NR) image quality assessment method that learns generalizable quality representations using a novel quality-aware contrastive loss for low-level features and fine-tuned vision-language models for high-level features.
- Combines low- and high-level features to predict image quality with minimal labeled data, and supports zero-shot quality prediction in a fully blind setting.
- Experiments across diverse datasets demonstrate strong generalizability and superior performance in data-efficient and zero-shot scenarios.
|
| 50 |
Quality-Aware Image-Text Alignment for Opinion-Unaware Image Quality Assessment |

Highlights:
- Proposed QualiCLIP, a self-supervised, opinion-unaware No-Reference Image Quality Assessment (NR-IQA) method that leverages CLIP to generate quality-aware image representations without human annotations.
- Introduces a quality-aware image-text alignment strategy by synthetically degrading pristine images and training CLIP to rank them according to similarity with quality-related antonym text prompts.
- Experiments show QualiCLIP outperforms existing opinion-unaware approaches and achieves competitive performance against supervised opinion-aware methods, demonstrating strong cross-dataset generalization.
|
| Spring 2025 |
Robotics Reading Group Papers |
| 49 |
AquaVis: A Perception-Aware Autonomous Navigation Framework for Underwater Vehicles |

Highlights:
- Introduced AquaVis, the first real-time, visibility-aware navigation framework for Autonomous Underwater Vehicles (AUVs) to track multiple visual objectives with arbitrary camera configurations.
- Enables AUVs to efficiently navigate in 3D, avoid obstacles, reach goals, and maximize visibility of objectives along the path while maintaining low computational overhead.
- Experimental results demonstrate improved tracking of multiple points of interest with fast re-planning times, suitable for single or multi-camera setups
|
| 48 |
State-of-the-Art Review on the Acoustic Emission Source Localization Techniques |

Highlights:
- Reviews acoustic emission (AE) source localization techniques in civil engineering, including Modal AE, Neural Networks, Beamforming, and Triangulation, with or without prior wave velocity knowledge.
- Evaluates methods based on sensor count, structural geometry, and overall performance, highlighting strengths and limitations of each approach.
- Suggests that deep learning with circular sensor clusters offers a promising, low-cost, and reliable solution for AE source localization.
|
| 47 |
Diffraction- and Reflection-Aware Multiple Sound Source Localization |

Highlights:
- Presented a novel indoor localization method for multiple sources using backward ray tracing combined with a uniform theory of diffraction to estimate primary, reflection, and diffraction sound paths.
- Supports stationary and moving sources, including human speech and clapping sounds, while handling non-line-of-sight sources and distinguishing active from inactive states.
- Evaluated in 7 m × 7 m rooms, achieving average localization errors of 0.65 m (single source) and 0.74 m (multiple sources), improving accuracy by 130% over prior work.
|
| 46 |
Underwater Acoustic Localization for Small Submersibles |
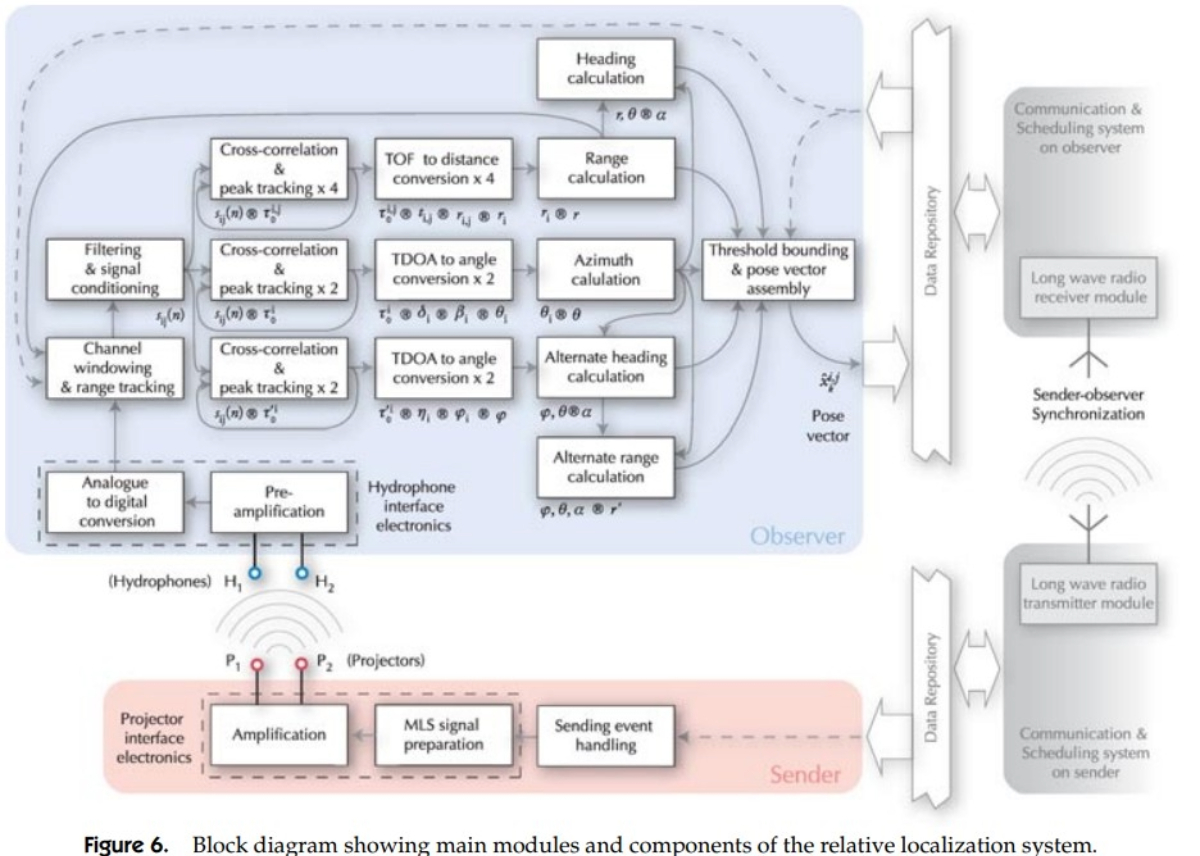
Highlights:
- Developed a high-precision, robust underwater localization method capable of measuring range, azimuth, and relative heading up to 90 m, with 0.05 m range and 2–5° angular precision for ranges up to 10 m
- Designed for swarm deployment using time-slot separation and maximum length sequence (MLS) acoustic signals, exploiting MLS broadband characteristics for accurate localization of neighboring vehicles.
- Integrated with a radio-based swarm communication system to enhance measurement precision and robustness, with capabilities and limitations validated through experiments.
|
| 45 |
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection |
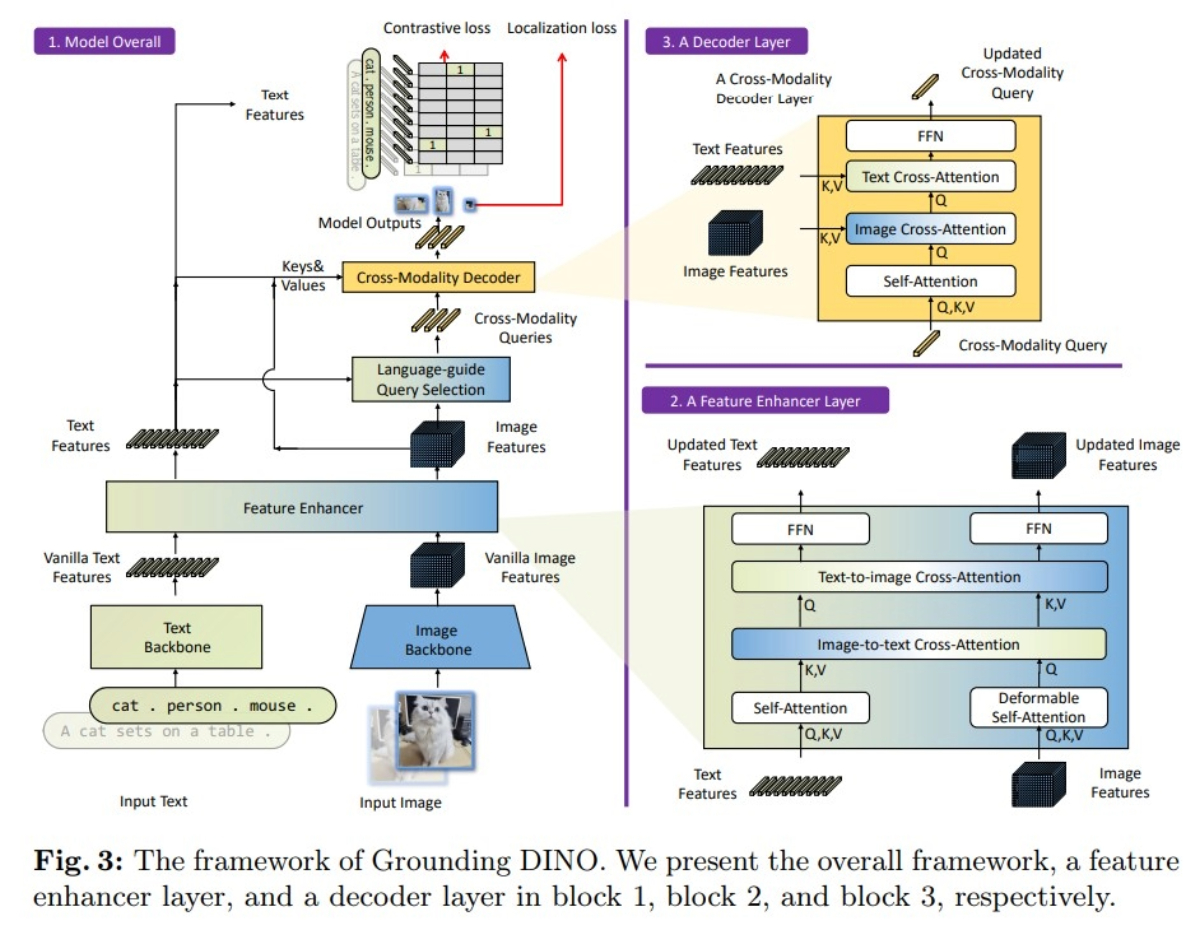
Highlights:
- Developed Grounding DINO, an open-set object detector that integrates language inputs with a Transformer-based DINO detector to detect arbitrary objects from category names or referring expressions
- Introduced a tight fusion approach with a feature enhancer, language-guided query selection, and cross-modality decoder to effectively combine vision and language modalities.
- Experimental results show the framework reduces data size to 0.8% of the original while achieving high-quality, semantically accurate image reconstruction, outperforming existing methods.Pre-trained on large-scale detection, grounding, and caption datasets, Grounding DINO achieves state-of-the-art zero-shot performance on COCO, LVIS, ODinW, and RefCOCO benchmarks, including 52.5 AP on COCO zero-shot detection.
|
| 44 |
Semantic Communication based on Large Language Model for Underwater Image Transmission |

Highlights:
- Proposed a novel Semantic Communication (SC) framework for underwater environments, leveraging visual Large Language Models (LLMs) to prioritize and compress image data based on user queries.
- Uses LLM-based recovery combined with Global Vision ControlNet and Key Region ControlNet networks to reconstruct images, enhancing communication efficiency and robustness.
- Experimental results show the framework reduces data size to 0.8% of the original while achieving high-quality, semantically accurate image reconstruction, outperforming existing methods.
|
| 43 |
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities |
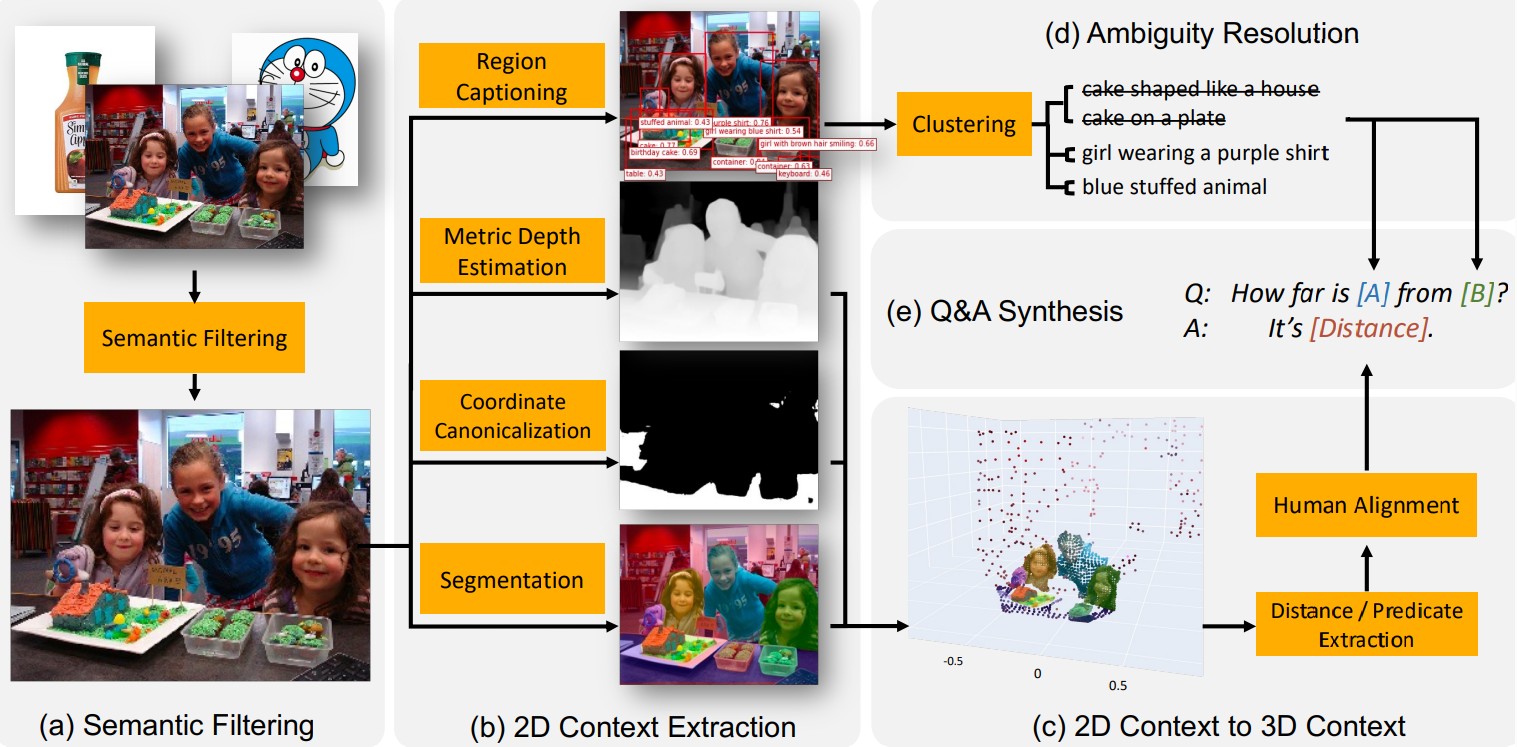
Highlights:
- Developed an automatic framework to generate an Internet-scale 3D spatial VQA dataset, producing up to 2 billion examples on 10 million real-world images to improve spatial reasoning in Vision-Language Models (VLMs).
- Investigated training factors including data quality, pipeline, and VLM architecture, enhancing both qualitative and quantitative 3D spatial reasoning performance.
- Demonstrated that the trained VLM enables novel applications in chain-of-thought spatial reasoning and robotics through its improved quantitative estimation capabilities.
|
| 42 |
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action |
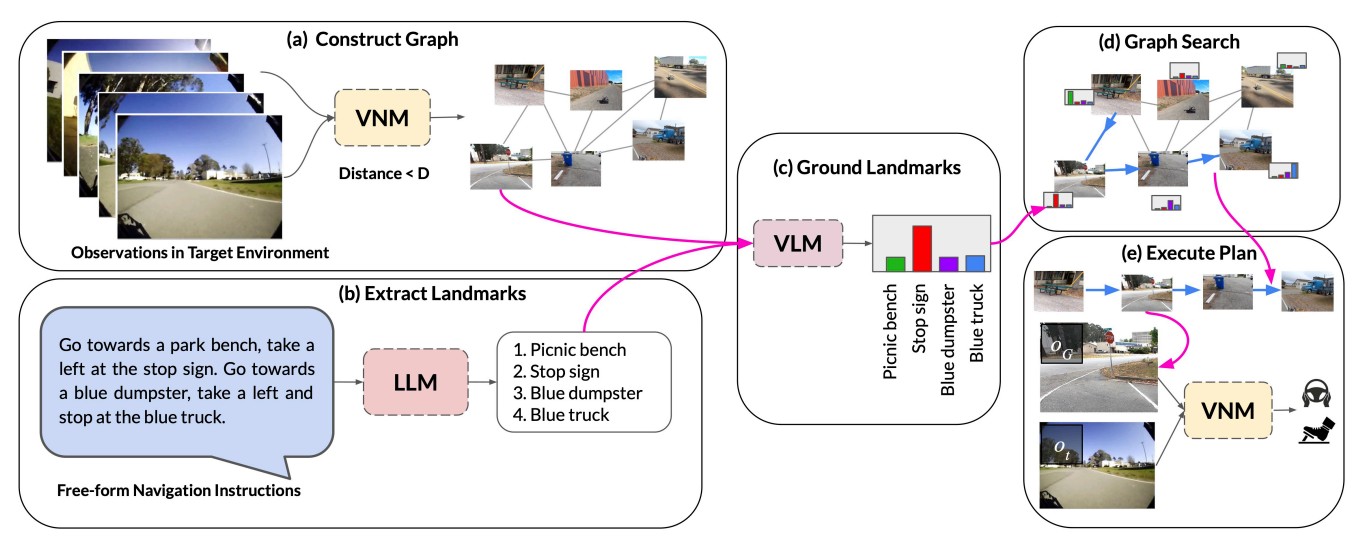
Highlights:
- Introduced LM-Nav, a robotic navigation system that enables goal-conditioned navigation from natural language instructions without requiring language-annotated robot data.
- Combines pre-trained models for navigation (ViNG), image-language association (CLIP), and language modeling (GPT-3) to extract landmarks, ground them visually, and navigate toward them.
- Demonstrated on a real-world mobile robot, achieving long-horizon navigation in complex outdoor environments using natural language instructions.
|
| 41 |
VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation |
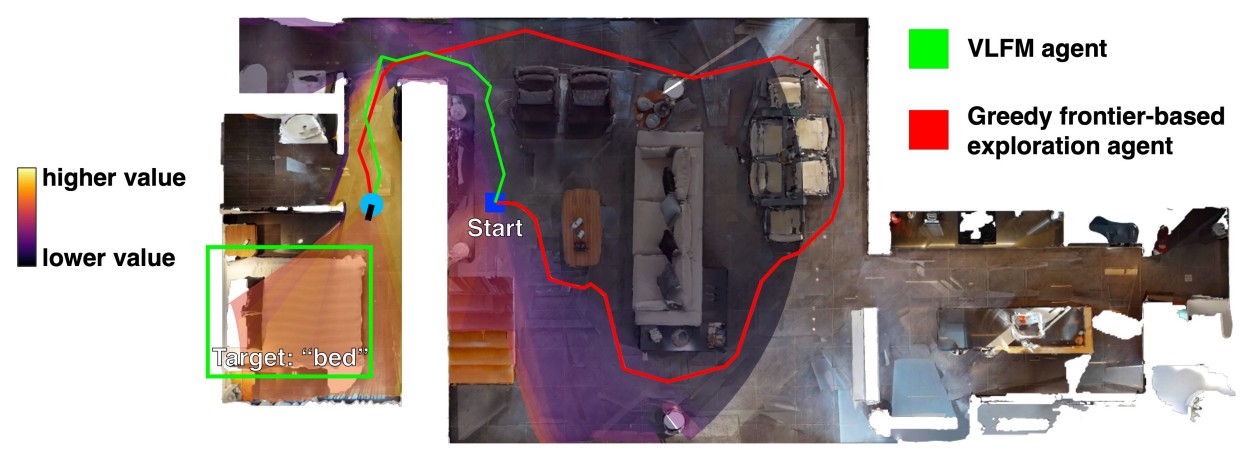
Highlights:
- Introduced Vision-Language Frontier Maps (VLFM), a zero-shot navigation approach inspired by human reasoning, enabling robots to find unseen semantic objects in novel environments.
- Combines depth-based occupancy maps with RGB observations and pre-trained vision-language models to generate language-grounded value maps, guiding exploration toward promising frontiers.
- Achieves state-of-the-art Object Goal Navigation results on Gibson, HM3D, and MP3D datasets, and demonstrates real-world deployment on Boston Dynamics Spot, efficiently navigating unknown office environments.
|
| 40 |
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models |
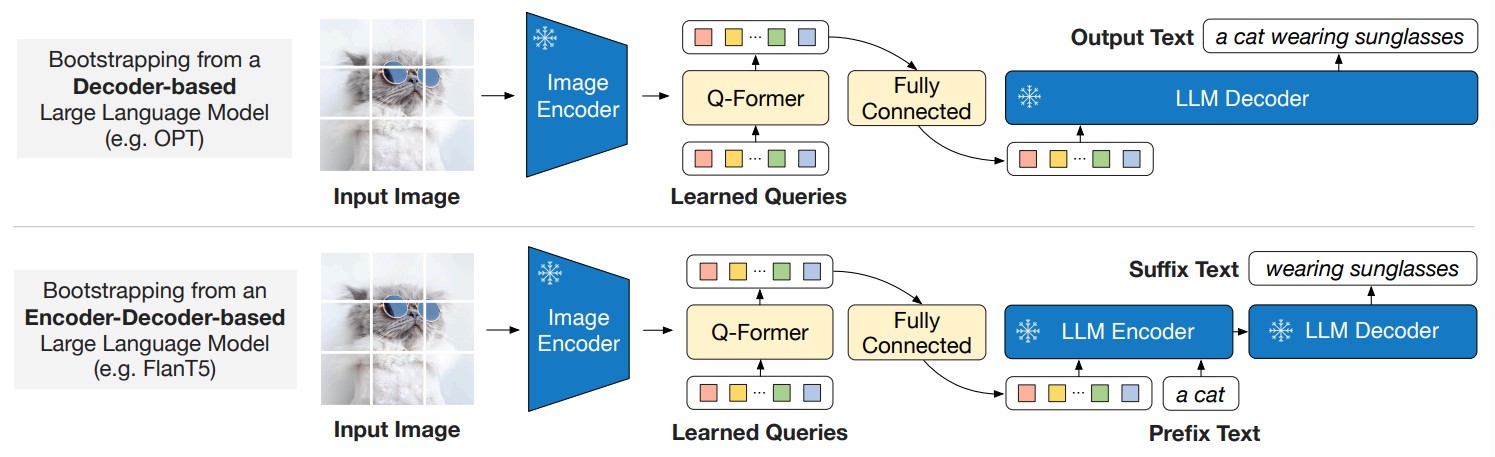
Highlights:
- Introduced BLIP-2, an efficient vision-and-language pretraining strategy that leverages frozen pre-trained image encoders and large language models.
- Uses a lightweight Querying Transformer pretrained in two stages to bridge the modality gap and enable vision-language representation and generative learning.
- Achieves state-of-the-art performance on multiple vision-language tasks with far fewer trainable parameters, outperforming Flamingo80B on zero-shot VQAv2 by 8.7% and enabling zero-shot image-to-text generation.
|
| 39 |
Modifications to ArduSub That Improve BlueROV SITL Accuracy and Design of Hybrid Autopilot |

Highlights:
- Implemented and validated improvements to ArduSub for the BlueROV2 Heavy, enhancing simulation accuracy and enabling autonomous controller design using real-world and literature data.
- Developed a ROS-based PD controller for angular DOF, outlined a method to determine PD gains for desired closed-loop performance, and verified results through step response and frequency response testing.
- Full six-DOF simulation demonstrated excellent tracking, with simulation-derived settings yielding comparable real-world performance.
|
| 38 |
Impedance Control of Robots: An Overview |

Highlights:
- Provides an overview of impedance control concepts, principles, and implementation strategies for achieving desired mechanical interaction with uncertain environments.
- Highlights key research challenges, open problems, and areas of interest in the field.
- Aims to guide readers in identifying relevant impedance control problems and selecting suitable strategies and solutions.
|
| 37 |
Design, Control, and Experimental Evaluation of a Novel Robotic Glove System for Patients With Brachial Plexus Injuries |

Highlights:
- Developed a portable exoskeleton glove system with linear and rotary series elastic actuators and optimized finger linkages to restore grasping functionality for brachial plexus injury patients.
- Investigated design and optimization strategies to balance functionality, portability, and stability, and compared model-based and model-free force control methods.
- Experimental results from 150 trials with three subjects demonstrated accurate force control and the glove’s potential as a rehabilitation device.
|
| 36 |
Design and Development of the Cable Actuated Finger Exoskeleton for Hand Rehabilitation Following Stroke |

Highlights:
- Developed the Cable Actuated Finger Exoskeleton (CAFE), a 3-DOF robotic exoskeleton for the index finger, addressing limitations of current hand rehabilitation devices in providing independent joint control and sufficient velocity/torque.
- Designed to explore a wide range of training paradigms for stroke rehabilitation, enabling targeted and versatile therapy.
- Presented the CAFE’s design, development, and performance testing results, demonstrating its potential for enhancing finger rehabilitation outcomes.
|
| 35 |
Safe haptic teleoperations of admittance controlled robots with virtualization of the force feedback |
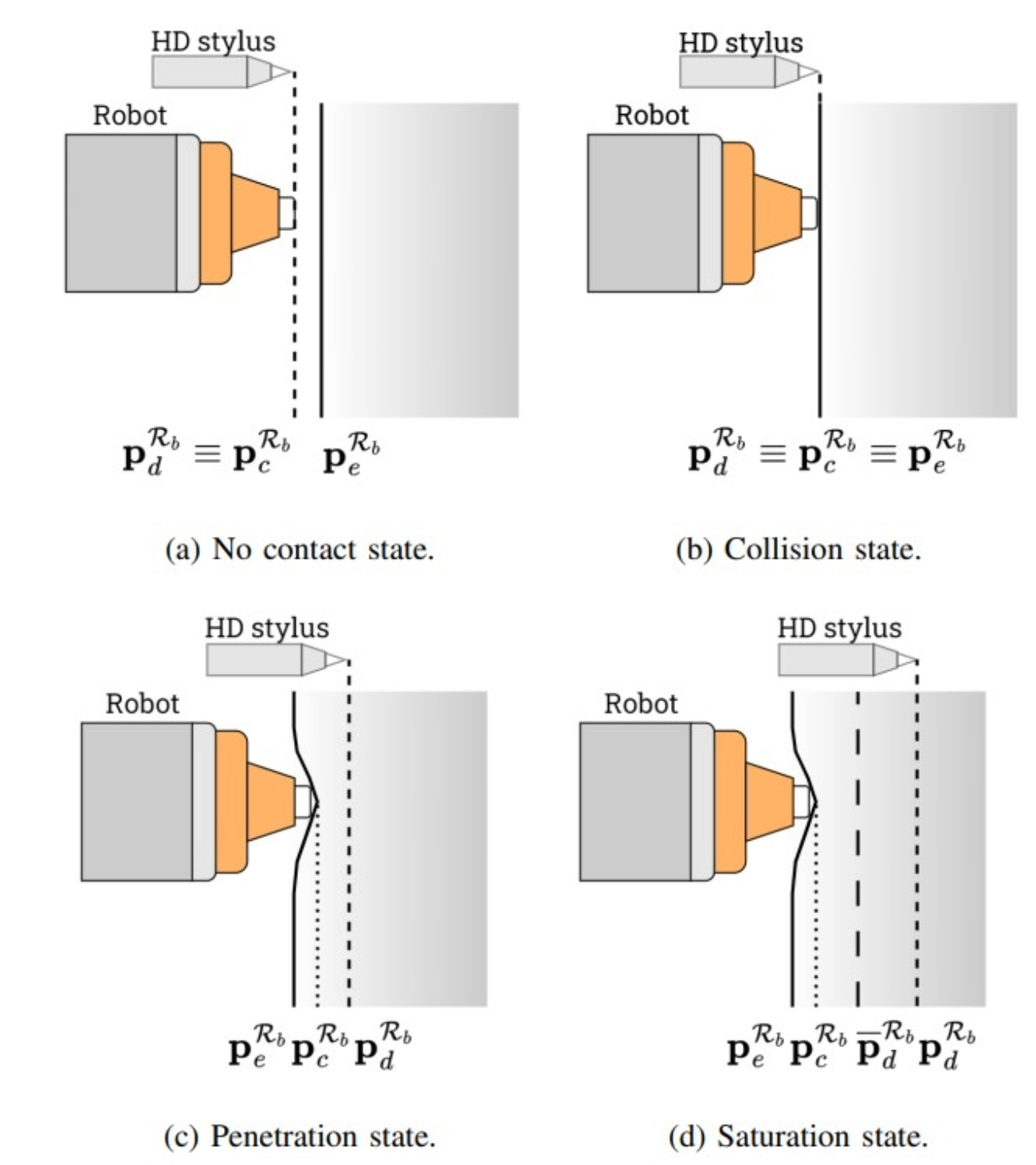
Highlights:
- Developed a novel haptic bilateral teleoperation system (HBTS) with virtualized force feedback based on motion error from an admittance-controlled robot, enabling separate tuning of force rendering and interaction control.
- Incorporated a motion reference saturation strategy to limit forces exerted on the environment, ensuring safe and stable human–robot interaction.
- Validated through a teleoperated blackboard writing experiment, showing improved naturalness, safety, and accuracy compared to two other architectures.
|
| 34 |
A Portable Intuitive Haptic Device on a Desk for User-Friendly Teleoperation of a Cable-Driven Parallel Robot |

Highlights:
- Developed a compact, portable cable-driven parallel robot (CDPR) haptic device with the same configuration as a larger fully constrained slave CDPR for intuitive teleoperation.
- Implemented admittance control for stiffness adjustment on an embedded microprocessor-based controller, enabling easy desktop installation.
- Experimental teleoperation tests with the portable CDPR as master and larger CDPR as slave demonstrated synchronized motion, intuitive remote control, and realistic force feedback.
|
| 33 |
Design and Calibration of a New 6 DOF Haptic Device |

Highlights:
- Designed and calibrated a new 6-DOF hybrid haptic device combining double parallel linkage, rhombus linkage, rotating structure, and grasping interface for large workspace, high output capability, and multi-finger interaction.
- Incorporated an adjustable base allowing operators to change posture without interrupting tasks, enhancing usability in teleoperation and virtual environment interactions.
- Experimental evaluation using a 3D sliding platform and force gauge analyzed position tracking and static force accuracy, with four application examples demonstrating the device’s potential.
|
| 32 |
Modeling and impedance control of a 6-DOF haptic teleoperation syste |
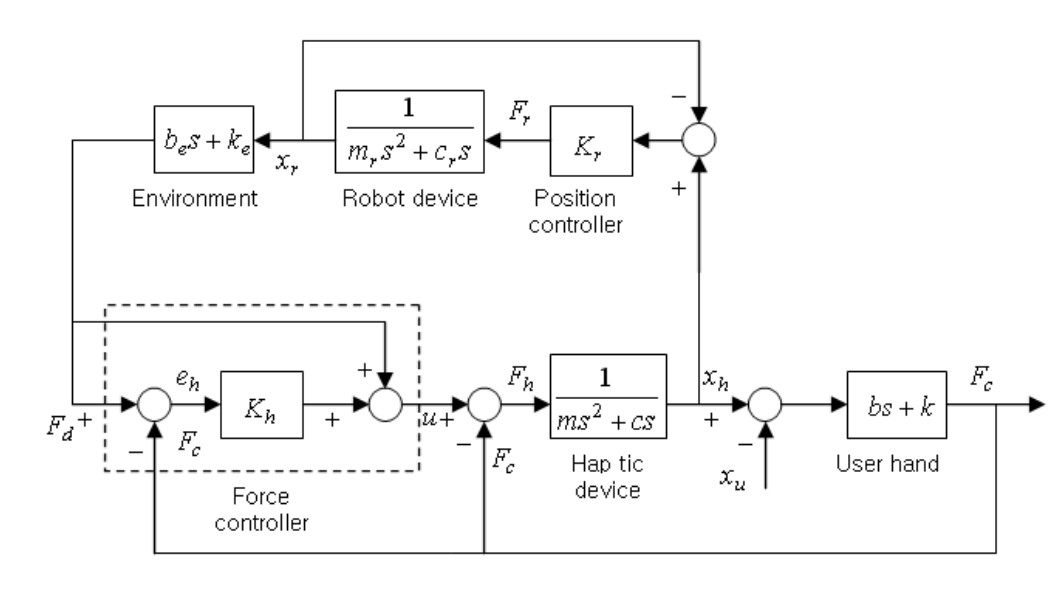
Highlights:
- Proposed a new dynamic model and impedance control algorithm for a haptic feedback device in robotic teleoperation, treating user-applied forces as system disturbances.
- Developed a self-tuning Fuzzy PID control scheme that adjusts PID parameters in real time based on environment–slave and human–device contact forces.
- Experimental results demonstrate improved transparency and accurate force tracking in a 6-DOF haptic teleoperation system.
|
| 31 |
A New 6-DOF Haptic Device for Teleoperation of 6-DOF Serial Robots |

Highlights:
- Developed a new 6-DOF parallel haptic device combining two 3-DOF parallel structures with a steering handle, meeting requirements for low inertia, fast motion, large orientation range, and high torque output.
- Analyzed kinematics, static force relationships, and implemented closed-loop impedance force control for teleoperation of a 6-DOF serial robot.
- Experimental results show that the closed-loop control effectively compensates dynamic forces during teleoperation.
|
| 30 |
Calibration and Closed-Loop Control Improve Performance of a Force Feedback Device |

Highlights:
- Developed a calibration method and closed-loop control strategy to enhance force feedback accuracy in motor-driven force feedback devices, particularly during high dynamic motions.
- Modeled and decoupled error sources while integrating force and current data, achieving substantial reductions in force feedback errors in both static and dynamic tests.
- Human-in-the-loop experiments showed up to ~93% reduction in mean absolute and relative absolute errors, confirming the method’s effectiveness for similar devices.
|
| Fall 2024 |
3D Vision Papers |
| 29 |
Hydra-Multi: Collaborative Online Construction of 3D Scene Graphs with Multi-Robot Teams |
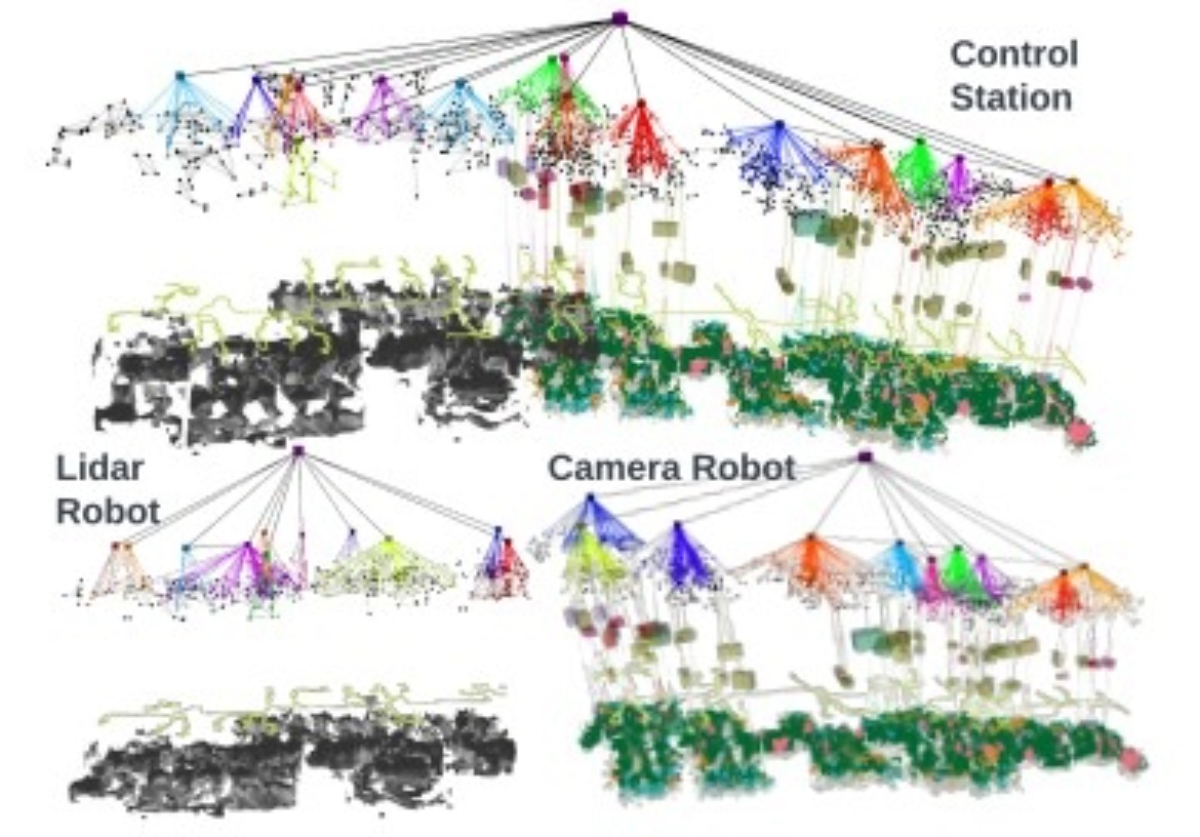
Highlights:
- Hydra-Multi is the first multi-robot system that can build a joint 3D scene graph online from data collected by multiple robots.
- It uses a centralized approach to align robots’ frames, integrate loop closure detections, and merge scene graph nodes across robots.
- The system works with both simulated and real-world data, producing accurate 3D scene graphs in real time.
- It supports heterogeneous robot teams by fusing map data from robots with different sensor types.
|
| 28 |
Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems |
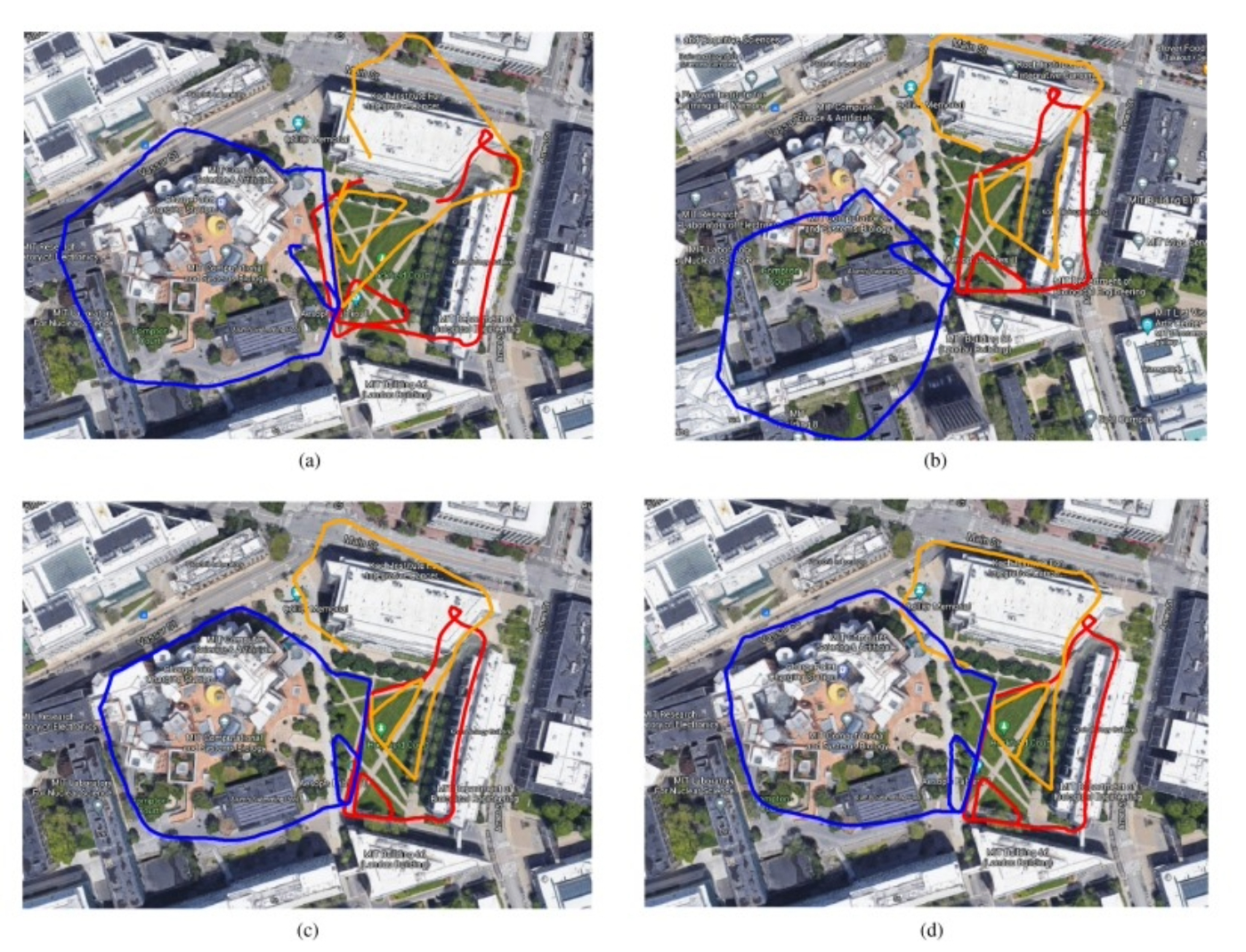
Highlights:
- Kimera-Multi enables distributed multi-robot SLAM that is robust to perceptual aliasing and does not require centralized communication.
- It generates globally consistent metric-semantic 3D meshes in real time using visual-inertial sensor data.
- The system uses peer-to-peer place recognition and robust pose graph optimization to improve trajectory estimates with low bandwidth usage.
- Experiments in simulations and real-world datasets show it outperforms existing methods in robustness and accuracy while matching centralized SLAM performance.
|
| 27 |
Comparative performance investigations of the intervention-class underwater vehicle with different possible thruster configurations using eight identical thrusters |
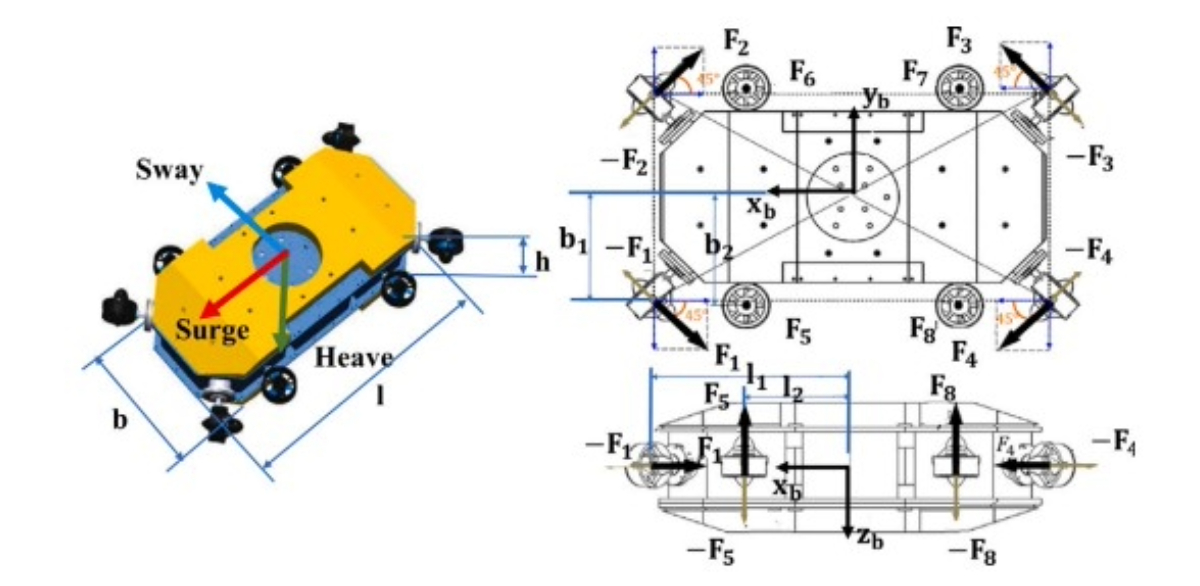
Highlights:
- The study compares different thruster configurations (TCs) for underwater vehicles using eight identical thrusters on a common platform through computer-based simulations.
- Performance is evaluated in terms of position error, orientation error, and energy consumption under various trajectory tracking tasks and underwater current conditions.
- Vectored horizontal and 3D vectored TCs consume more energy compared to horizontal and vertical TCs.
- Horizontal and vertical TCs show 30% and 23% lower energy consumption than 3D vectored TCs in the absence and presence of underwater currents, respectively.
|
| 26 |
Optimization of thruster configuration and control allocation for a spherical magnetic coupling thrusters actuated underwater robot |

Highlights:
- System design – Introduces the SRMCT-II, a lightweight and compact 3-DOF spherical reconfigurable magnetic coupling thruster for underwater robots, offering vectored thrust and watertightness.
- Optimization approach – Uses a genetic algorithm to determine the optimal layout of three SRMCT-IIs for improved agility, removing reliance on engineer intuition.
- Control allocation – Formulates control allocation as a constrained convex optimization problem, solved via an augmented Lagrangian method, to assign motion commands efficiently.
- Experimental validation – Tests on a custom force-sensing platform confirm vectored thrust capability, computational efficiency, accurate control allocation, and complete decoupling of thrust and torque in all three dimensions.
|
| 25 |
A Novel Parametrization of the Perspective-Three-Point Problem for a
Direct Computation of Absolute Camera Position and Orientation |
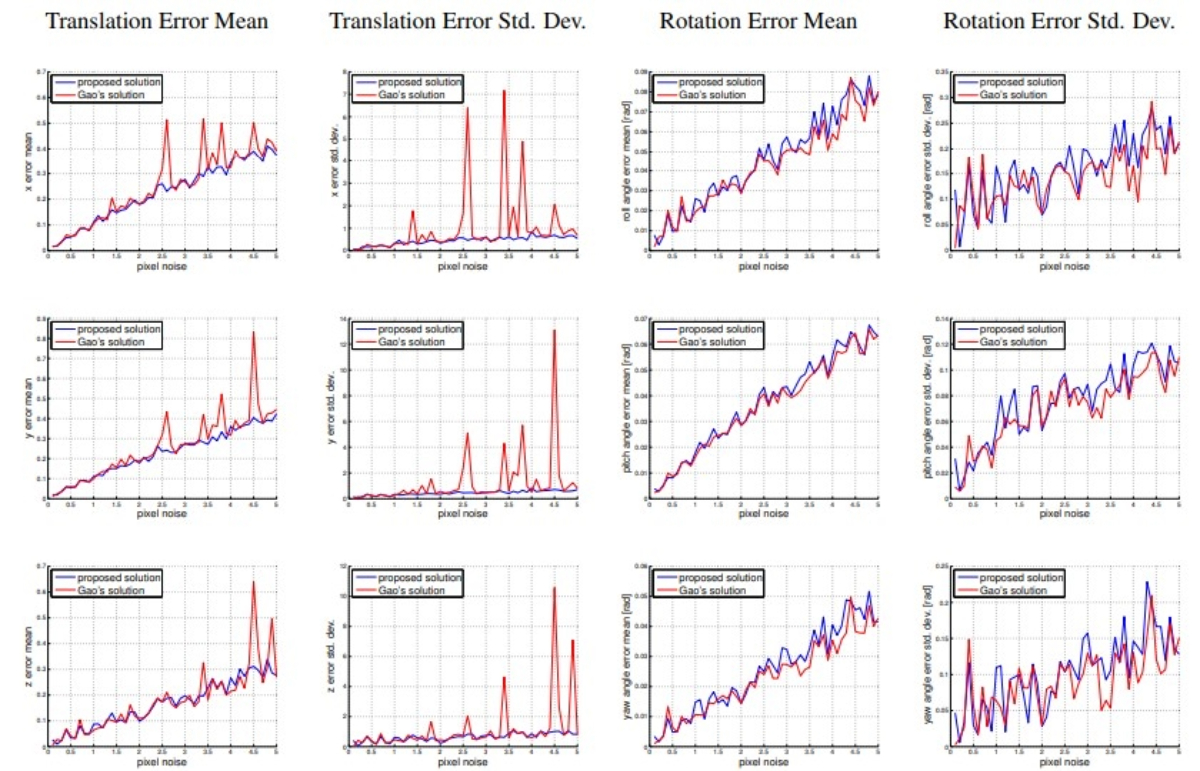
Highlights:
- Goal of P3P – Determine the camera’s position and orientation from three 2D–3D correspondences, which can yield up to four possible solutions, disambiguated by a fourth point.
- Novel approach – Instead of solving for 3D point positions in the camera frame first, the proposed method directly computes the aligning transformation in one stage using intermediate camera and world frames with only two parameters.
- Mathematical formulation – Projection leads to two conditions and a quartic equation, producing up to four solutions, followed by back-substitution to obtain the camera poses.
- Advantages – Comparable accuracy to standard methods but ~15× faster, with better numerical stability and robustness to degenerate configurations, making it well-suited for RANSAC-based outlier rejection before PnP or nonlinear refinement.
|
| 24 |
An Efficient Algebraic Solution to the Perspective-Three-Point Problem |
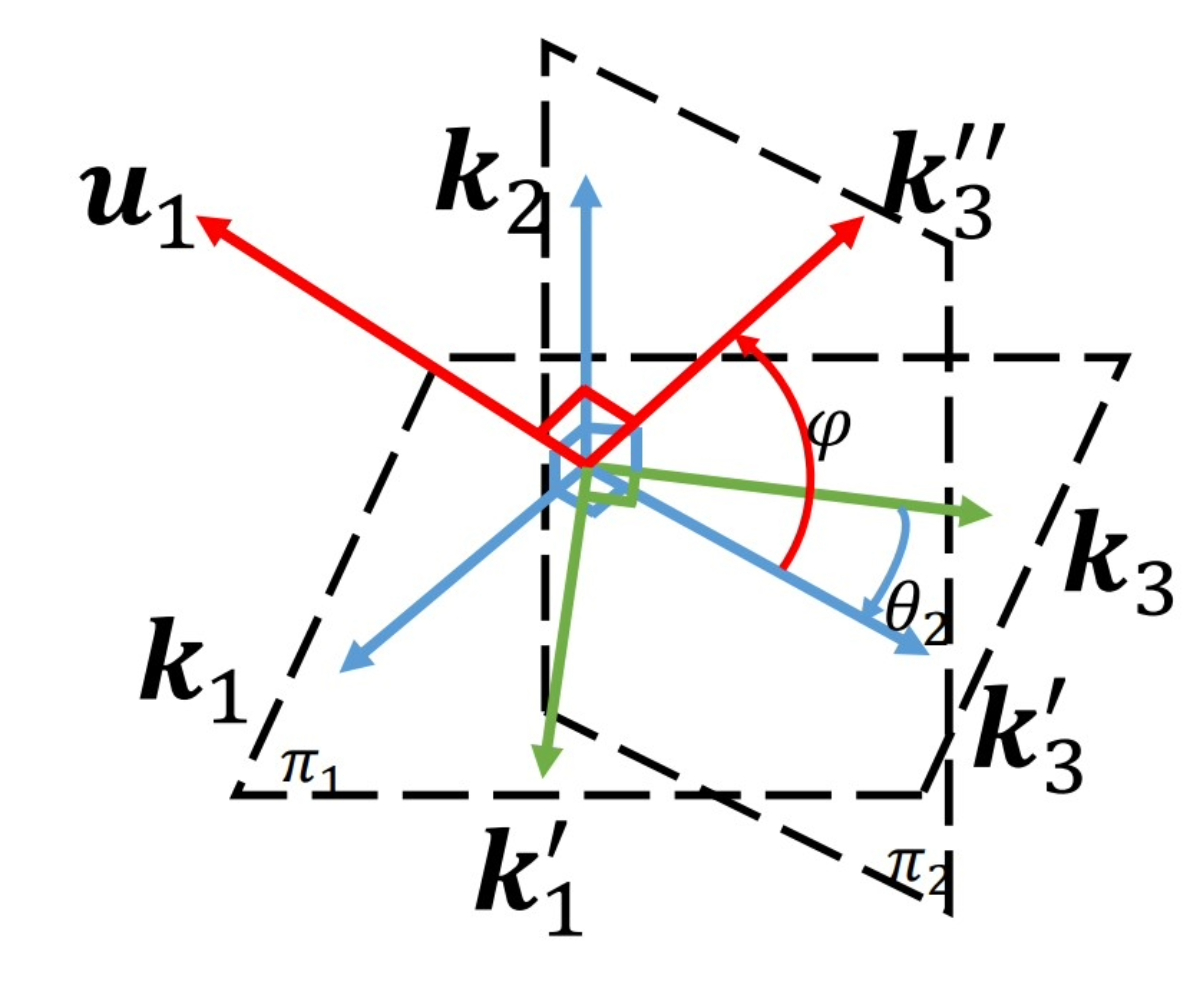
Highlights:
- Goal of the Work – Present an algebraic solution to the classical P3P problem to determine a camera’s position and orientation from three known reference points.
- Key Difference from Prior Work – Directly determine the camera’s orientation using geometric constraints to form trigonometric equations, rather than first calculating intermediate distances.
- Solution Approach – Solve these equations algebraically to obtain the rotation matrix, then compute the camera’s position.
- Performance & Validation – Avoids unnecessary, potentially unstable intermediate computations, resulting in higher accuracy, greater robustness, and lower computational cost, as confirmed by extensive Monte-Carlo simulations in both nominal and near-singular cases.
|
| 23 |
A computer model for underwater camera systems |
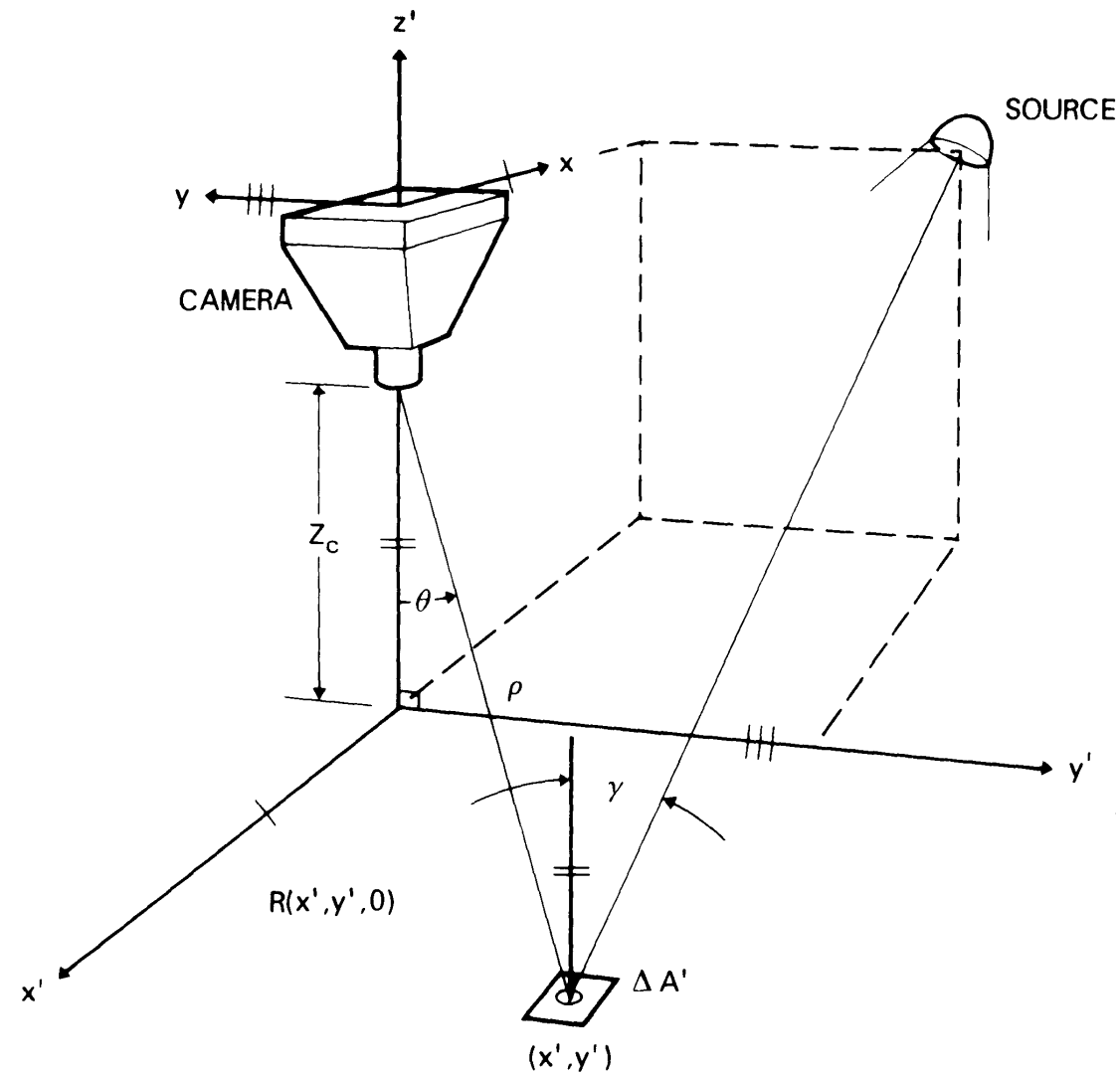
Highlights:
- The computational model is designed to calculate underwater camera image components by leveraging inputs such as system geometry, source properties, and water optical properties. It outputs key irradiance components, including non-scattered light, scattered light, and backscatter, along with derived metrics like contrast and signal-to-noise ratio (SNR). This model facilitates comprehensive performance analysis and provides sample calculations to support its application.
|
| 22 |
A revised underwater image formation model |
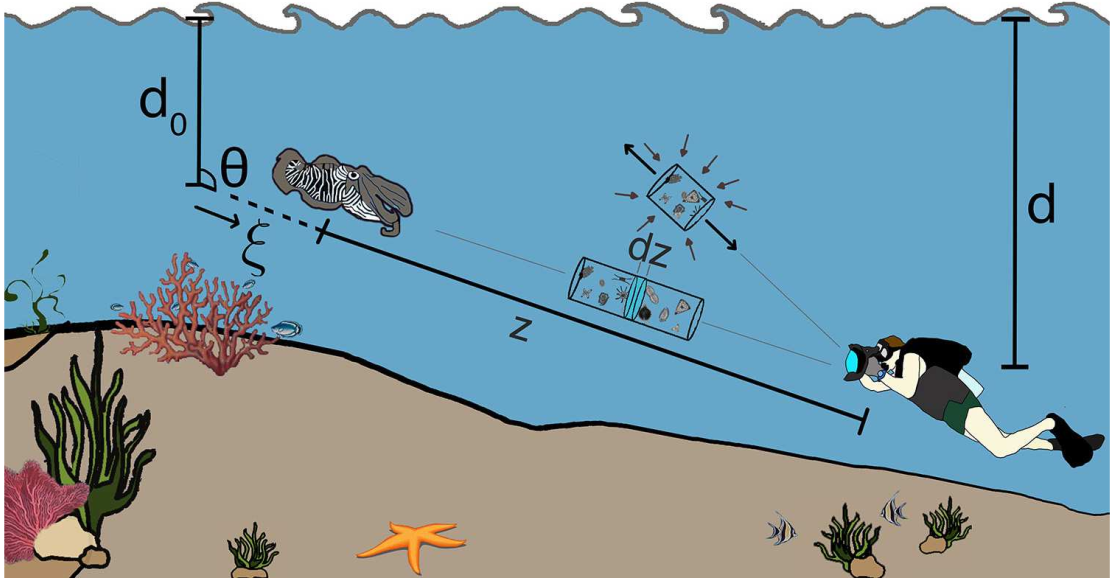
Highlights:
- The current underwater image models face a significant limitation in their assumption of similar coefficients for backscatter and direct transmission, which inaccurately represent real-world conditions. Key findings reveal that backscatter relies on distinct wavelength-dependent coefficients, a fact validated through oceanographic data. To address this, a revised model has been developed that accounts for these differences, significantly improving the accuracy of underwater images. This advancement resolves instabilities in color reconstruction and highlights the need for developing innovative methods to further enhance underwater imaging techniques.
|
| 21 |
Sea-thru: A method for removing water from underwater images |

Highlights:
- Color recovery in underwater images is challenged by the limitations of flawed atmospheric models. To overcome this, a revised model incorporates range-based attenuation and distinct backscatter coefficients, offering a more accurate representation of underwater light behavior. The Sea-thru method further enhances this approach by utilizing RGBD data to estimate backscatter and range-dependent attenuation. With results outperforming traditional atmospheric models on over 1,100 images from two different water bodies, this advancement significantly improves underwater image quality. The impact extends to enabling advanced computer vision and machine learning applications, driving progress in underwater exploration and conservation efforts.
|
| 20 |
3D Gaussian Splatting for Real-Time Radiance Field Rendering |

Highlights:
- Radiance field methods struggle with inefficiencies in real-time 1080p rendering at high quality. To address this, a novel approach leverages 3D Gaussians, anisotropic optimization, and fast visibility-aware rendering techniques, enabling real-time performance. This solution achieves state-of-the-art quality while maintaining real-time rendering speeds of 30 frames per second or higher on established datasets, marking a significant advancement in rendering technology.
|
| 19 |
Single image haze removal using dark channel prior |

Highlights:
- The proposed method introduces the dark channel prior, a simple yet effective image statistic, for single-image haze removal. The key observation underlying this approach is that most haze-free outdoor image patches contain pixels with low intensity in at least one color channel. By combining this prior with the haze imaging model, the method estimates haze thickness and recovers clear images. The results demonstrate high-quality haze removal while also generating accurate depth maps as a valuable byproduct, showcasing the efficacy of this approach.
|
| 18 |
SeaThru-NeRF: Neural radiance fields in scattering media |
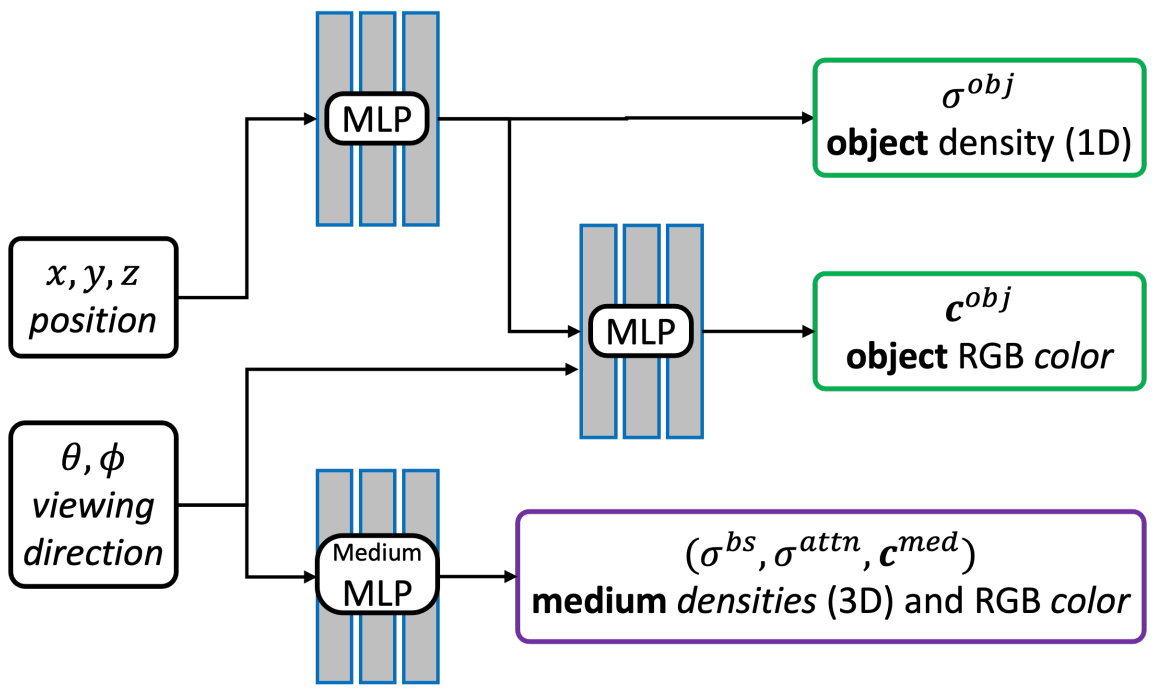
Highlights:
- Traditional NeRF models fail to account for the effects of scattering media in underwater or foggy scenes, limiting their applicability in such environments. To address this, a novel NeRF rendering model is developed using the SeaThru image formation framework. This approach successfully removes medium effects, revealing clear object appearances and accurate depths while achieving photorealistic views, significantly enhancing the realism and utility of NeRF in challenging visual environments.
|
| Summer 2024 |
Subsea Telerobotics and HMI Papers |
| 17 |
Demand-driven optimization method for thruster configuration of underwater vehicles considering capability boundary and system efficiency |

- The study addresses optimizing thruster configurations for underwater vehicles to improve performance based on position, orientation, and number of thrusters.
- A comprehensive model is proposed that considers energy consumption and operational trajectories, aiming to maximize system efficiency while meeting capability constraints.
- A comprehensive model is proposed that considers energy consumption and operational trajectories, aiming to maximize system efficiency while meeting capability constraints.
- Validation shows the optimized configuration reduces energy consumption by 20.34% compared to common configurations while meeting capability and speed requirements, offering practical design insights.
|
| 16 |
Deep Multi-view Depth Estimation with Predicted Uncertainty |
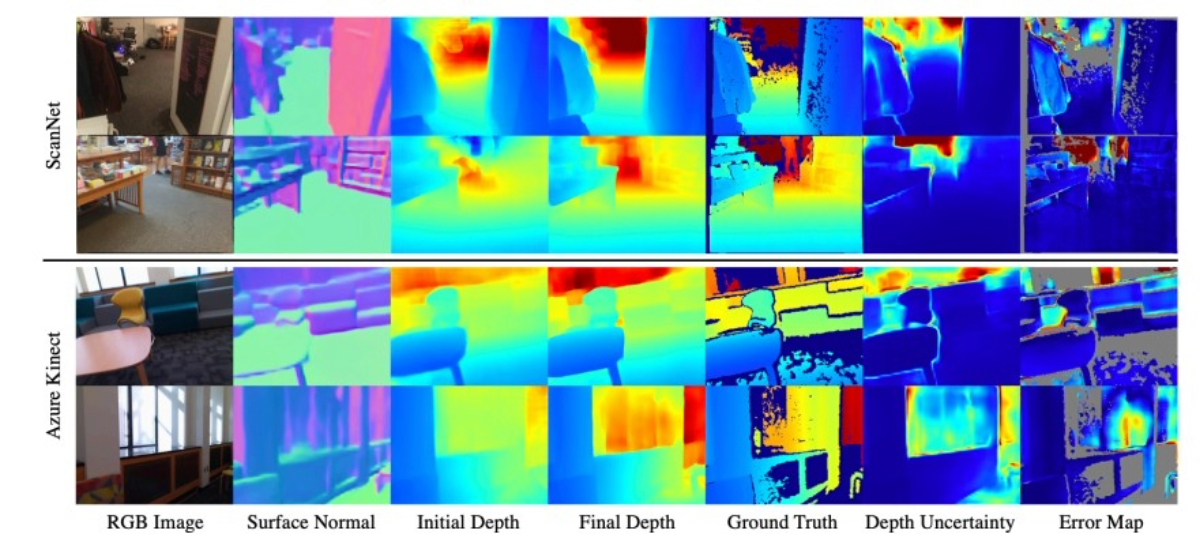
- The paper proposes estimating dense depth from image sequences using a dense-optical-flow network for initial triangulation
- A depth-refinement network (DRN) with an iterative refinement module (IRM) improves depth accuracy by leveraging image contextual cues.
- The DRN also predicts uncertainty in the refined depths, and experiments show the method outperforms state-of-the-art approaches in accuracy.
|
| 15 |
High-speed autonomous quadrotor navigation through visual and inertial paths |

- The paper focuses on autonomous indoor navigation for quadrotors using a pre-constructed visual map represented as a graph of linked images.
- The quadrotor employs wide- and short-baseline RANSACs with different point algorithms to determine motion toward reference images and handle special maneuvers.
- Incorporating gravity information allows faster and more efficient navigation using modified point algorithms.
- An adaptive optical-flow algorithm estimates horizontal velocity under challenging conditions, and the methods are validated experimentally in dynamic and complex indoor environments.
|
| 14 |
UUV Simulator: A Gazebo-based Package for Underwater Intervention and Multi-Robot Simulation |
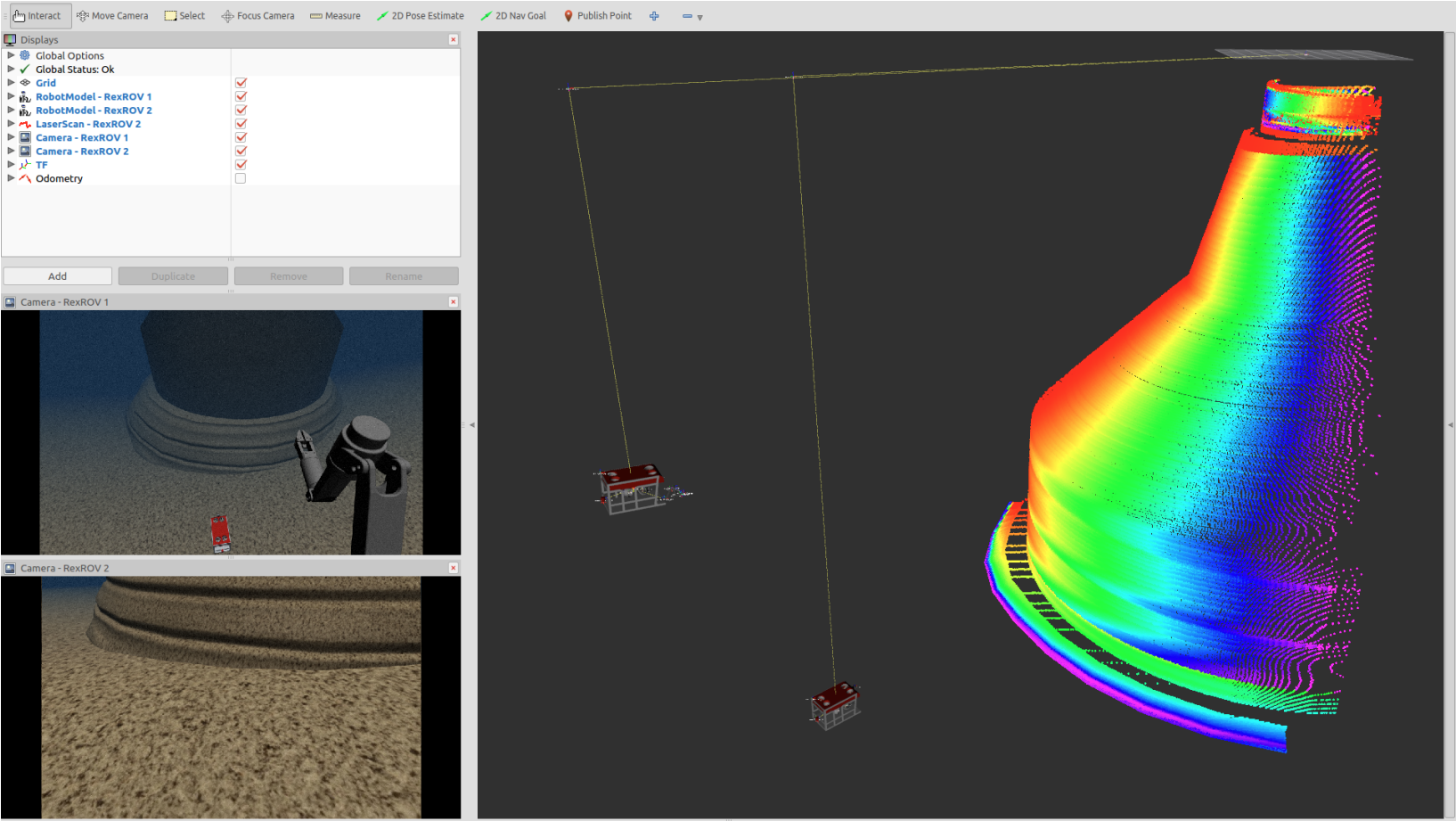
- A widely used open-source marine robotics simulator.
- Built upon OpenSceneGraph engine, ROS and Gazebo plugin available.
- An extensive collection of sensors: camera, IMU, magnetometer, DVL, MBES, sonar.
- Supports multiple ROVs: RexROV2, ECA A9, LAUV, Desistek SAGA ROV.
|
| 13 |
OceanPlan: Hierarchical Planning and Replanning for Natural Language AUV Piloting in Large-scale Unexplored Ocean Environments |

Highlights:
- LLM-based hierarchical motion planner for AUVs.
- First translates abstract human instructions to robotic tasks, then plans motion.
- A replanner to sense environmental uncertainties and adjust motion in real-time .
- Tested in HoloEco (built upon HoloOcean) simulator.
|
| 12 |
The PANDORA project: a success story in AUV autonomy |

Highlights:
- PANDORA (Persistent Autonomy Through Learning Adaptation Observation and Re-planning): a framework for autonomous underwater inspection and intervention.
- The AUV learns to inspect and manipulate from operator's demonstration.
- Adapts the knowledge for valve control in a different scenario. Tested with Girona 500 AUV in laboratory testbed.
- Follows and inspects a chain using acoustic and visual perception. Tested with Nessie AUV.
|
| 11 |
A Shared Autonomy System for Precise and Efficient Remote Underwater Manipulation |

Highlights:
- SHARC (Shared autonomy for remote collaboration): a framework for tele-manipulation with hand gesture and natural language.
- SHARC-VR: Real-time pose update of the manipulator shown in a 3D reconstructed scene to improve spatial awareness of operators.
- A shared autonomy framework where the robot autonomously pick up a tool upon operator command.
|
| 10 |
Sensory augmentation for subsea robot teleoperation |
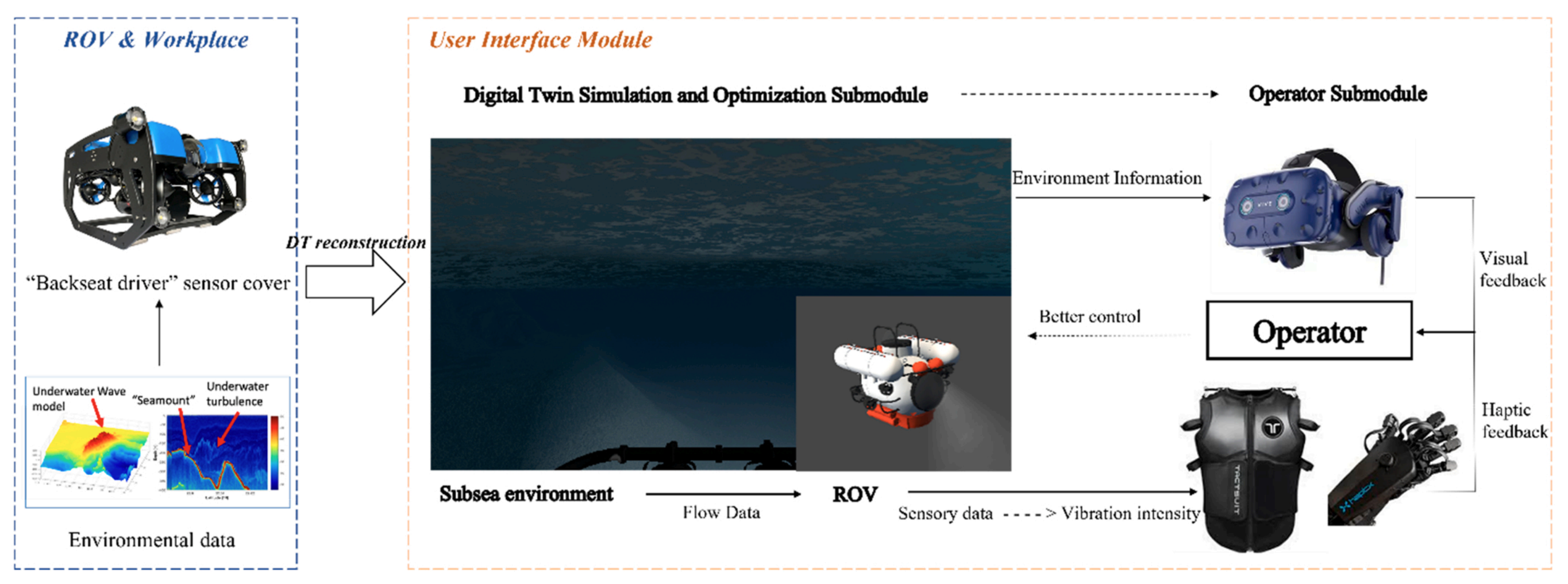
Highlights:
- Enhanced telepresence with VR and haptic sensation to improve ROV teleoperation.
- Hierarchical feedback for (i) near-field (vibration), and (ii) far-field (flow) hydrodynamic sensation.
- Virtual scene rendering and digital twin modeling from real deployment data.
|
| 2023 |
ViCom - Visual Computing Papers |
Presenter |
| 09 |
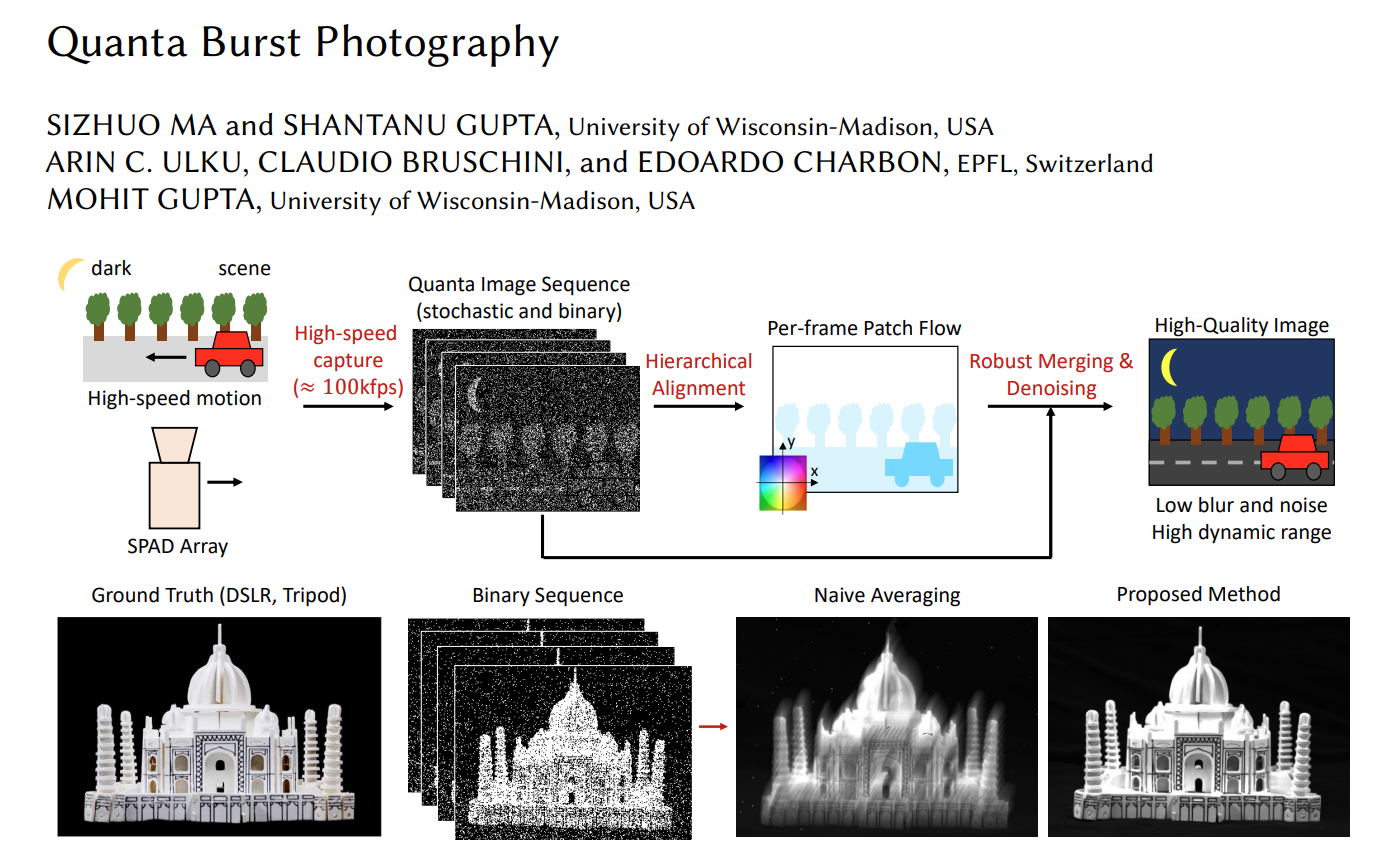
Quanta burst photography |
Brevin Tilmon |
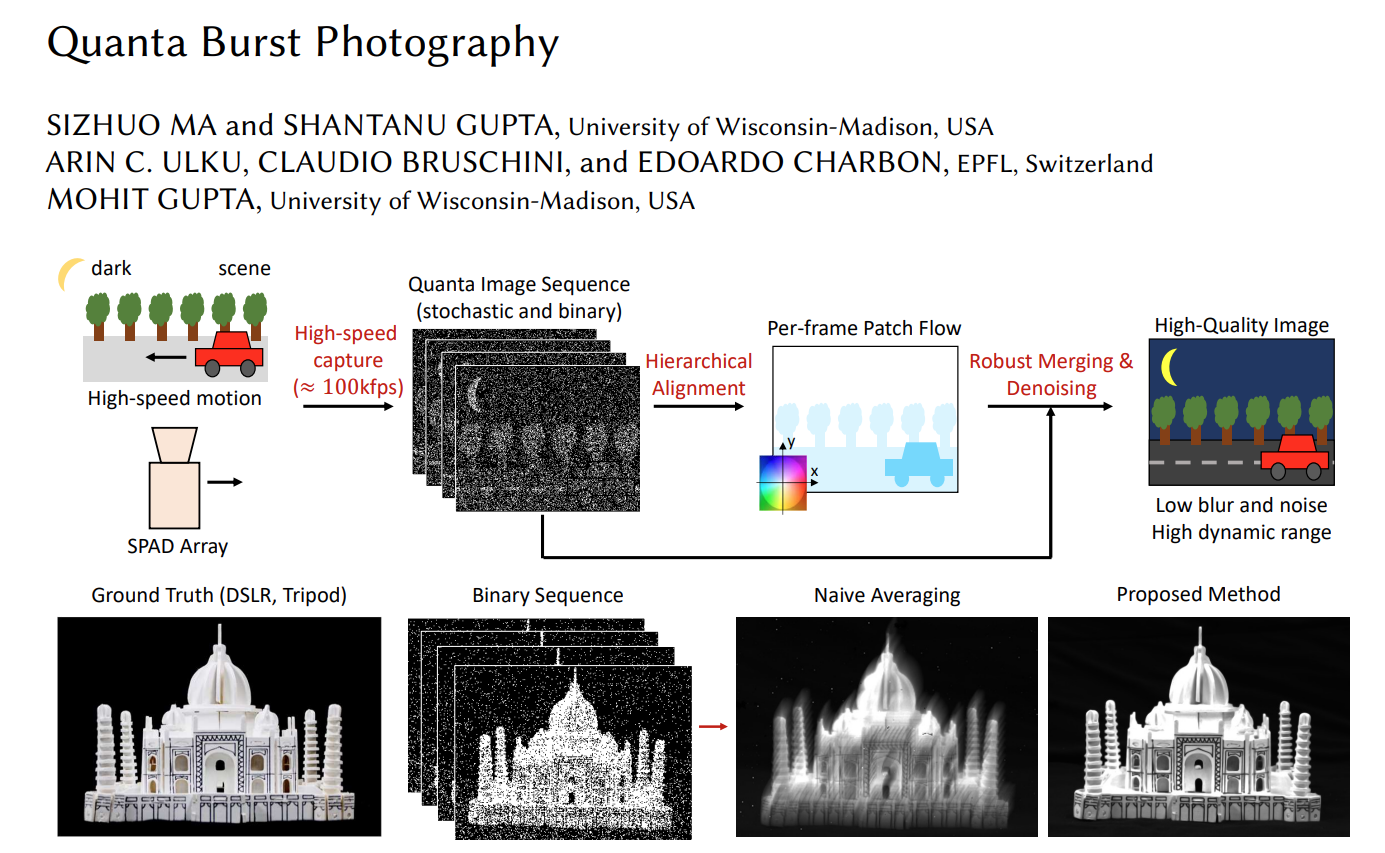
This paper theoretically analyzes the SNR and dynamic range of quanta burst photography, and identifies the
imaging regimes where it provides significant benefits. The authors demonstrate, via a recently developed SPAD array,
that the proposed method is able to generate high-quality images for scenes with challenging lighting, complex geometries,
high dynamic range and moving objects. With the ongoing development of SPAD arrays, the quanta burst photography has the potential to
find applications in both consumer and scientific photography.
|
| 08 |
Dual-Shutter Optical Vibration Sensing |
Hannah Kirkland |
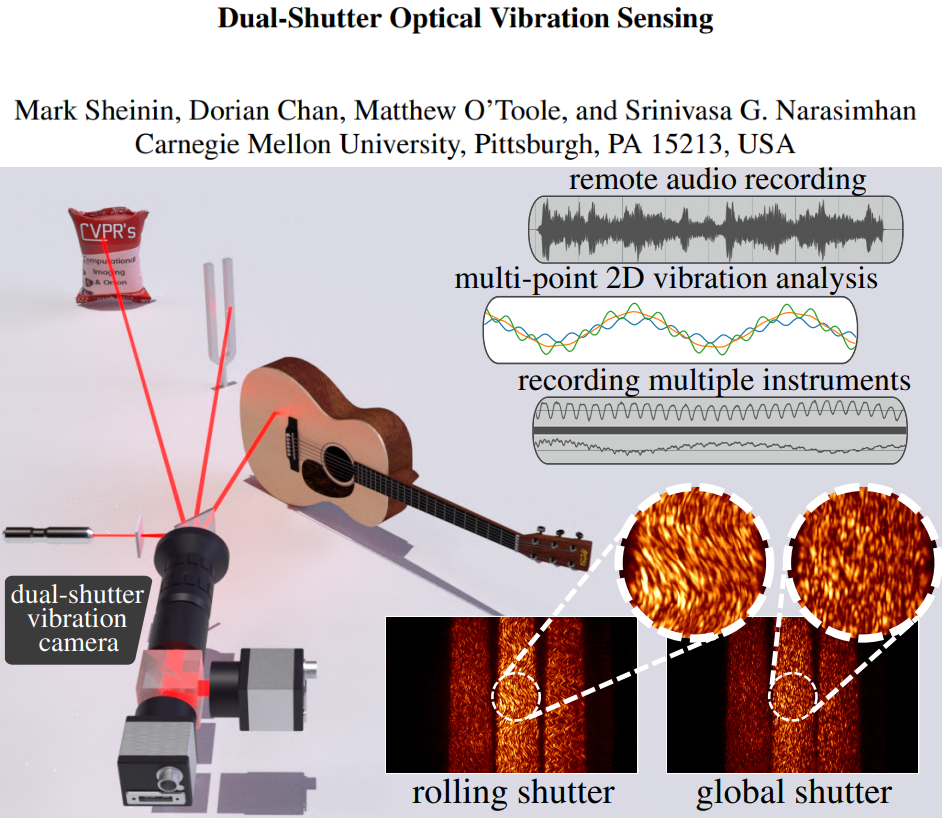
In this paper, a novel method for sensing vibrations at high speeds (up to 63kHz) is proposed, for multiple scene
sources at once, using sensors rated for only 130Hz operation. The method relies on simultaneously capturing the
scene with two cameras equipped with rolling and global shutter sensors, respectively. The rolling shutter camera
captures distorted speckle images that encode the highspeed object vibrations. The global shutter camera captures
undistorted reference images of the speckle pattern, helping to decode the source vibrations. The authors
demonstrate their method by capturing vibration caused by audio sources
(e.g. speakers, human voice, musical instruments) and analyzing the vibration modes of a tuning fork.
|
| 07 |
Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement |
Adnan Abdullah |
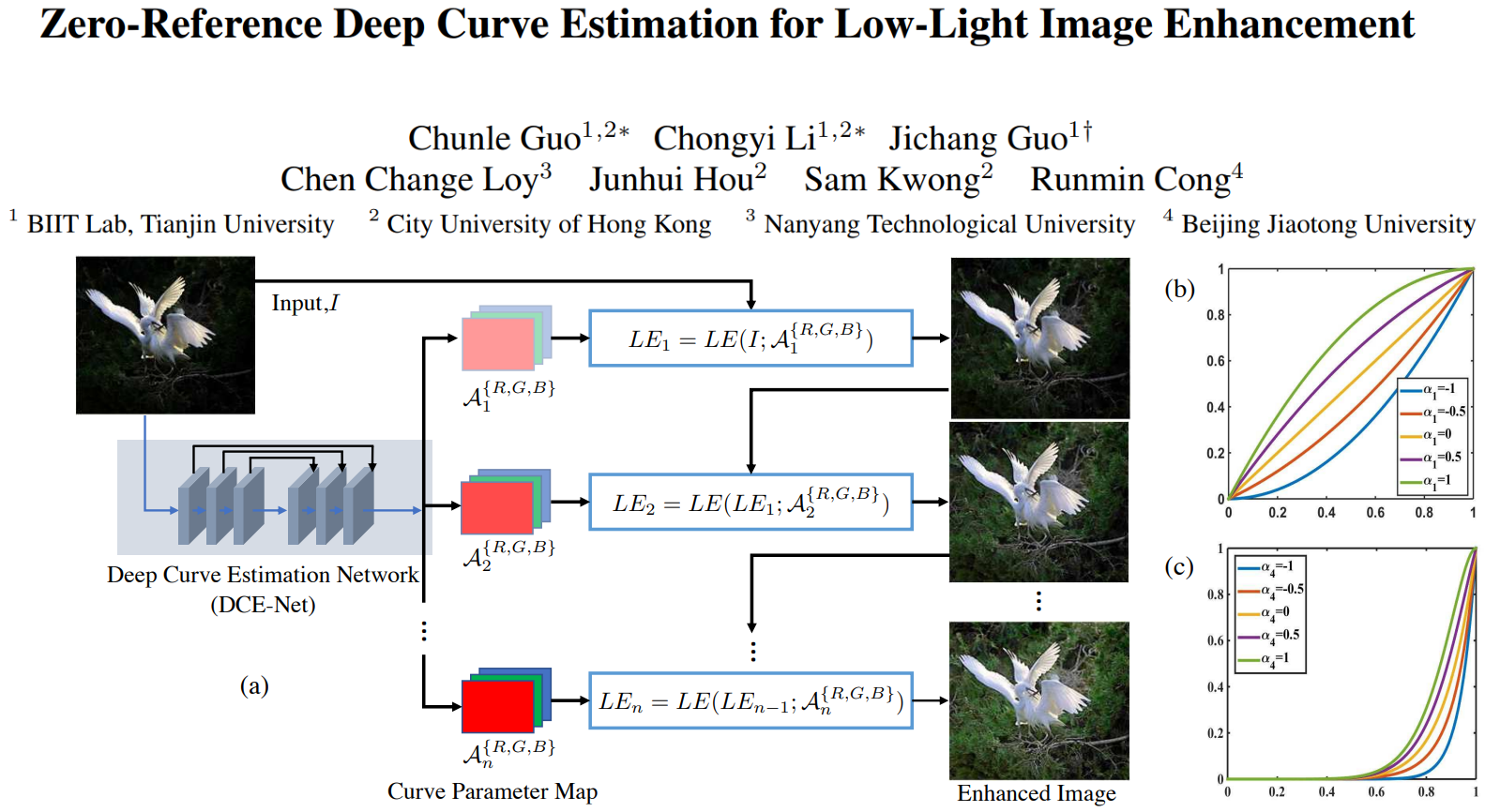
The authors propose the first low-light enhancement network that is independent of paired and unpaired training data, thus
avoiding the risk of overfitting. As a result, this method generalizes well to various lighting conditions. They design an
image-specific curve that is able to approximate pixel-wise and higher-order curves by iteratively applying itself. They also
show the potential of training a deep image enhancement model in the absence of reference images through task-specific non-reference
loss functions.
|
| 06 |
Toward Fast, Flexible, and Robust Low-Light Image Enhancement |
Boxiao Yu |
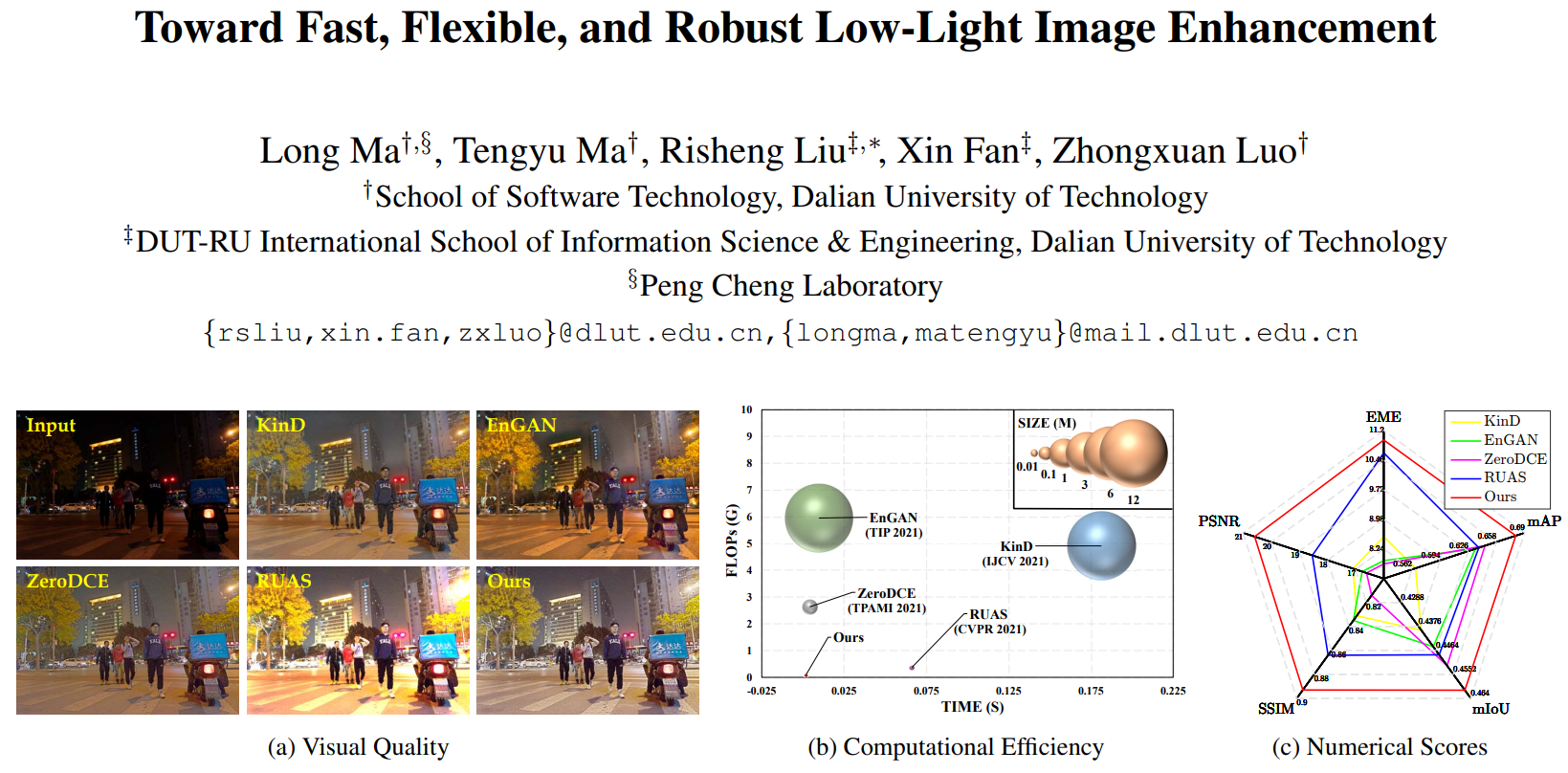
The authors develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening
images in real-world low-light scenarios. They define the unsupervised training loss to constrain the output of each stage under
the effects of selfcalibrated module, endowing the adaptation ability towards diverse scenes. In nutshell, SCI redefines the
peak-point in visual quality, computational efficiency, and performance on downstream tasks.
|
| 05 |
SVIn2: A multi-sensor fusion-based underwater SLAM system |
Adnan Abdullah |
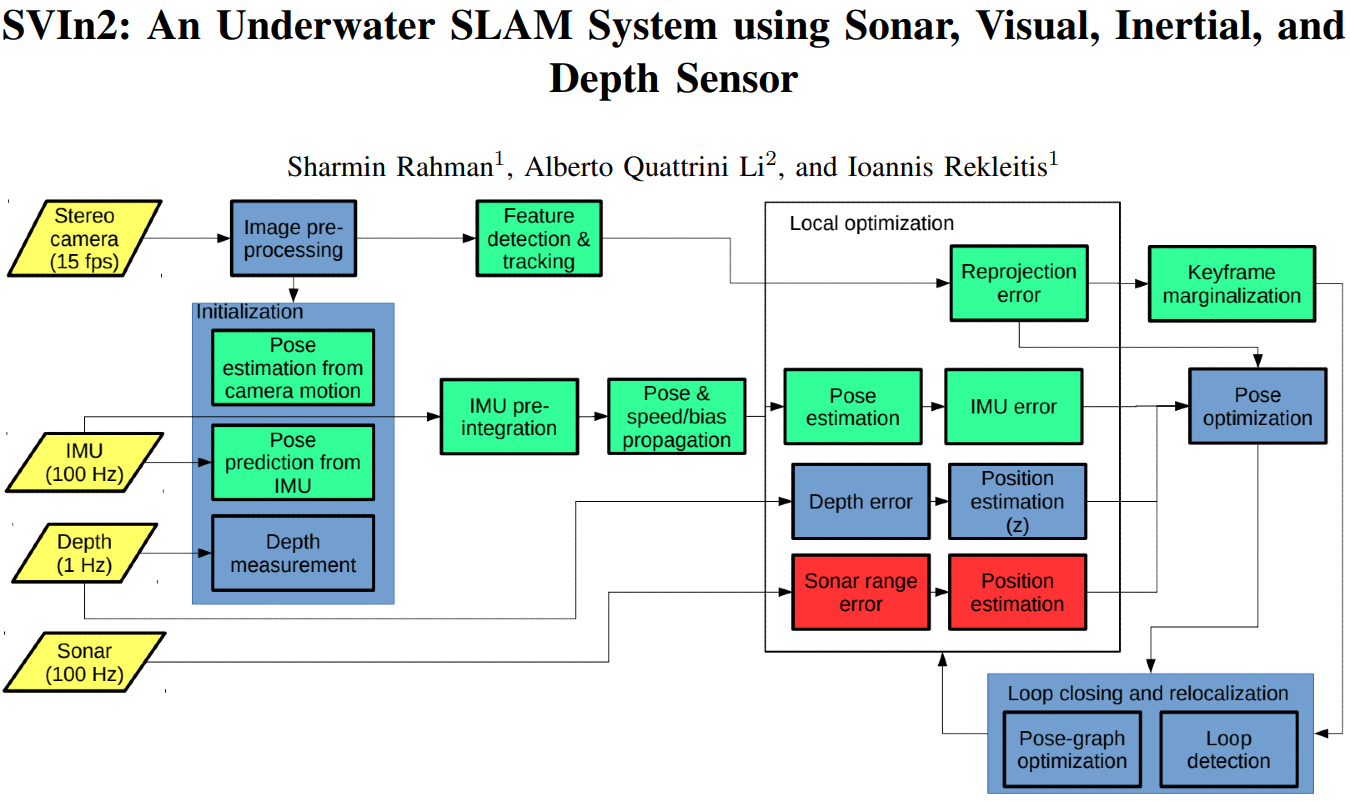
This paper presents a novel tightly-coupled keyframe-based Simultaneous Localization and Mapping (SLAM) system with loop-closing
and relocalization capabilities targeted for the underwater domain. This system is easily adaptable for
different sensor configuration: acoustic (mechanical scanning profiling sonar), visual (stereo camera), inertial (linear
accelerations and angular velocities), and depth data which makes the system versatile and applicable on-board of different
sensor suites and underwater vehicles.
|
| 04 |
Vision Transformer with Deformable Attention |
Jackson Arnold |
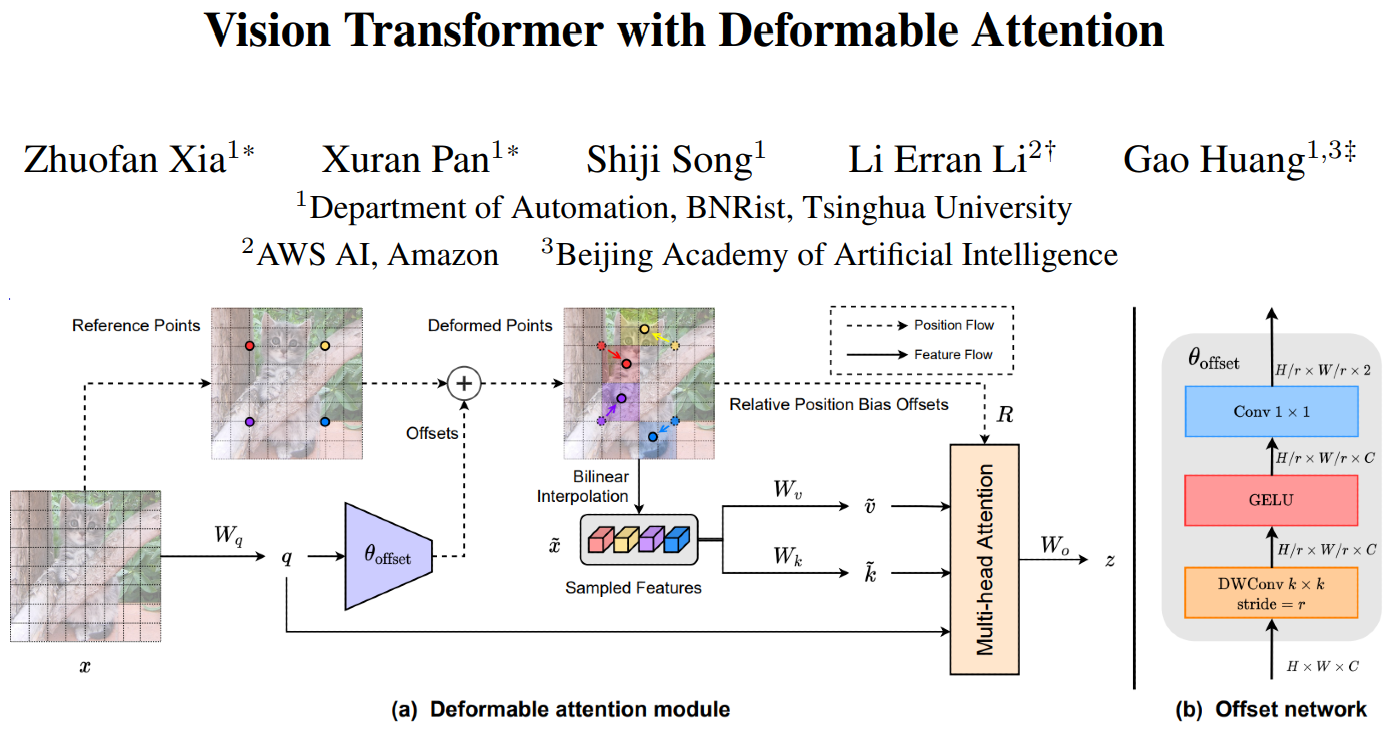
This paper proposes a novel deformable self-attention module, where the positions of key and value pairs in self-attention are
selected in a data-dependent way. This flexible scheme enables the self-attention module to focus on relevant regions and capture
more informative features. On this basis, the authors present Deformable Attention Transformer, a general
backbone model with deformable attention for both image classification and dense prediction tasks.
|
| 03 |
Holocurtains: Programming Light Curtains via Binary Holography |
Brevin Tilmon |
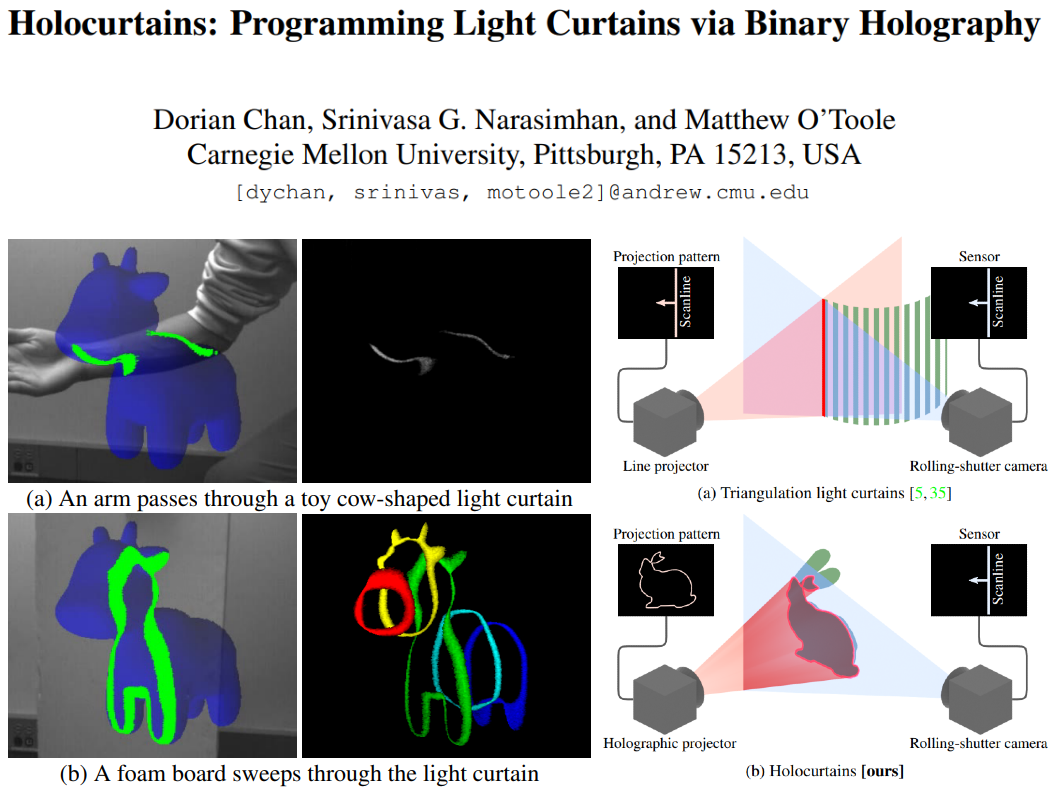
In this work, the authors propose Holocurtains: a light-efficient approach to producing light curtains of arbitrary shape. The
key idea is to synchronize a rolling-shutter camera with a 2D holographic projector, which steers (rather than block)
light to generate bright structured light patterns. their prototype projector uses a binary digital micromirror device (DMD) to
generate the holographic interference patterns at high speeds. This system produces 3D light curtains that cannot be achieved
with traditional light curtain setups and thus enables all-new applications, including the ability to simultaneously capture multiple
light curtains in a single frame, detect subtle changes in scene geometry, and transform any 3D surface into an optical touch interface.
|
| 02 |
Adiabatic Quantum Computing for Multi Object Tracking |
Hannah Kirkland |
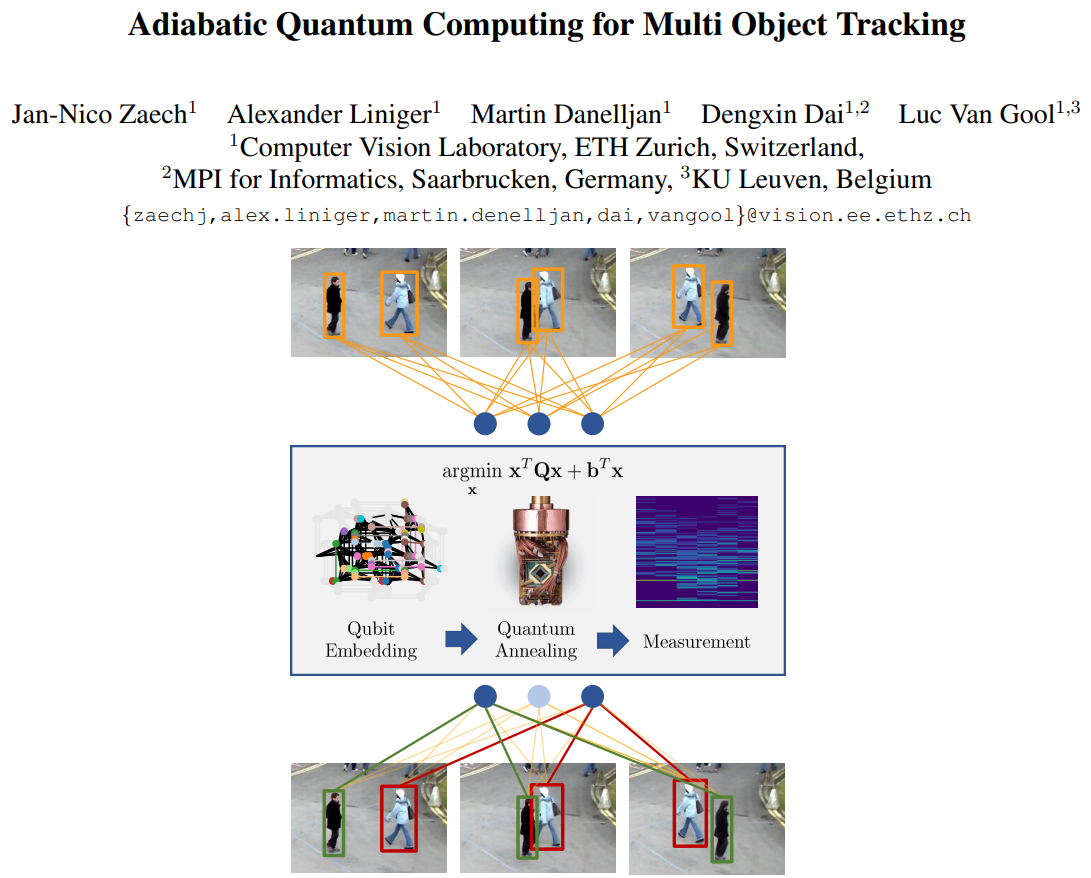
In this work, the authors propose the first Multi-Object Tracking (MOT) formulation designed to be solved with AQC. They employ an
Ising model that represents the quantum mechanical system implemented on the AQC. They show that their approach is competitive compared
with state-of-the-art optimization based approaches, even when using of-the-shelf integer programming solvers. Finally, they demonstrate that this MOT
problem is already solvable on the current generation of real quantum computers for small examples, and analyze the properties of the measured solutions.
|
| 01 |
Denoising Diffusion Probabilistic Models |
Boxiao Yu |
The authors present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models
inspired by considerations from nonequilibrium thermodynamics. The best results are obtained by training on a weighted variational
bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin
dynamics, and their models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of
autoregressive decoding.
|