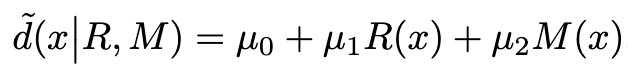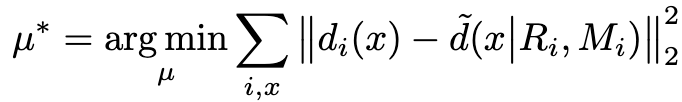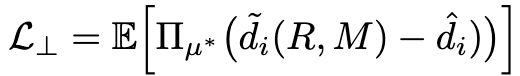IEEE International Conference on Robotics and Automation (ICRA 2023)
UDepth Overview
Underwater depth estimation is the foundation for numerous marine robotics tasks such as autonomous mapping and 3D reconstruction, visual filtering, tracking and servoing, navigation,
photometry and imaging technologies, and more. Unlike terrestrial robots, visually guided underwater robots have very few low-cost solutions for dense 3D visual sensing because of
the high cost and domain-specific operational complexities involved in deploying underwater LiDARs, RGB-D cameras, or laser scanners. Our team presents a robust and efficient
end-to-end model UDepth, for fast underwater monocular depth estimation.
We make several contributions to the UDepth learning pipeline:
• We adapt a new input space for underwater domain-aware learning for monocular depth estimation.
• We design an eifficient domain projection step for coarse depth prediction.
• We further devise a novel domain projection loss to enforce the attenuation constraints in the holistic learning process.
Experimental results show that our model offers comparable and often better depth estimation performance than SOTA models with only 20% computational cost.
Our method can facilitate the 3D perception capabilities of autonomous low-cost underwater robots, making it possible for real-time exploration.
RMI Input Space. First, we adapt a RMI input space from raw RGB image space based on underwater light characteristics of propagation.
We exploit the fact that red wavelength suffers more aggressive attenuation underwater,
so the relative differences between {R} channel and {G, B} channel values can provide useful depth information for a given pixel.
As illustrated in this figure, differences in R and M values vary proportionately with pixel distances, as demonstrated by six 20 × 20 RoIs selected on the left image.
We exploit these inherent relationships and demonstrate that RMI≡{R, M=max{G,B}, I (intensity)} is a significantly better input space for visual learning pipelines of underwater monocular depth estimation models.
Our experimental results show that both UDepth and SOTA models exhibit consistently better results when trained on the RMI input space instead of raw RGB inputs.
Domain projection. Based on the wavelength-dependent attenuation constraints of the underwater domain, we design a domain projection step for pixel-wise coarse depth prediction.
We express the R-M relationship with the depth of the pixel with a linear approximator, then we find an efficient least-squared formulation by optimizing on the RGB-D training pairs.
We futher extend our domain projection step with guided filtering for fast coarse depth prediction.
The domain projection achieves 51.5 FPS rates on single-board Jetson TX2s.
Domain projection Loss. Following the domain projection, we extend it into a domain projection loss that guides the end-to-end learning of UDepth.
We express the R-M relationship with the depth of a pixel x with a linear approximator as follows:
Then, we find the least-squared solution μ* on the entire RGB-D training pairs, which is over 2.8 billion pixels (9229images of 640 × 480 resolution) by optimizing:
We find μ* = [0.496, −0.389, 0.464] in our experiments on USOD10K dataset.
Here, our goal is to use the optimal μ-space for regularization, we penalize any pixel-wise depth predictions that violate the underwater image attenuation constraint.
We achieve this by the following projection error function:
End-to-end Learning Pipeline
The network architecture of UDepth model consists of three major components: a MobileNetV2-based encoder-decoder backbone, a transformer-based refinement module (mViT), and a convolutional regressor.
These components are tied sequentially for the supervised learning of monocular depth estimation.
Raw RGB images are first pre-processed to map into RMI input space;
then forwarded to the MobileNetV2 backbone for feature extraction;
those features are refined by the mViT module to combine adaptive global information with local pixel-level information from CNN;
the following convolutional regression generate the final single channel depth prediction.
The learning objective involves pixel-wise losses and the novel domain projection loss.
MobileNetV2 backbone. We use an encoder-decoder backbone based on MobileNetV2 as it is highly efficient and designed for resource-constrained platforms.
It is considerably faster than other SOTA alternatives with only a slight compromise in performance, which makes it feasible for robot deployments. It is based on an inverted residual structure with residual connections between bottleneck layers.
The intermediate expansion layers use lightweight depthwise convolutions to filter features as a source of non-linearity.
The encoder contains a series of fully convolution layers with 32 filters, followed by a total of 19 residual bottleneck layers.
We adapt the last convolutional layer of decoder so that it finally generates 48 filters of 320 × 480 resolution, given a 3-channel RMI input.
mViT refinement. Transformers can perform global statistical analysis on images, solving the problem that traditional convolution models can only handle pixel-level information.
Due to the heavy computational cost of Vision Transformers (ViT), we adopt a lighter mViT architecture inspired by.
The 48 filters extracted by the backbone are 1×1 convolved and flattened to patch embeddings, which serve as inputs to the mViT encoder.
Those are also fed to a 3×3 convolutional layer for spatial refinements.
The 1×1 convolutional kernels are subsequently exploited to compute the range-attention maps R, which combines adaptive global information with local pixel-level information from CNN.
The other embedding is propagated to a multilayer perceptron head with ReLU activation to obtain a 80-dimensional bin-width feature vector fb.
Convolutional regression. Finally, the convolutional regression module combines the range-attention maps R and features fb to generate the final feature map f.
To avoid discretization of depth values, the final prediction of depth map D is computed by the linear combination of bin-width centers.
Monocular Depth Estimation Performance
Qualitative performance
We compare our UDepth model with some SOTA monocular depth estimation models on USOD10K test set.
As seen, UDepth infers accurate and consistent depth predictions across various waterbody, attenuation levels, and lighting conditions.
UDepth offers comparable and often better performance than its closest competitor baseline Adabins, while offering 5× faster inference and memory efficiency.
Quantitative performance
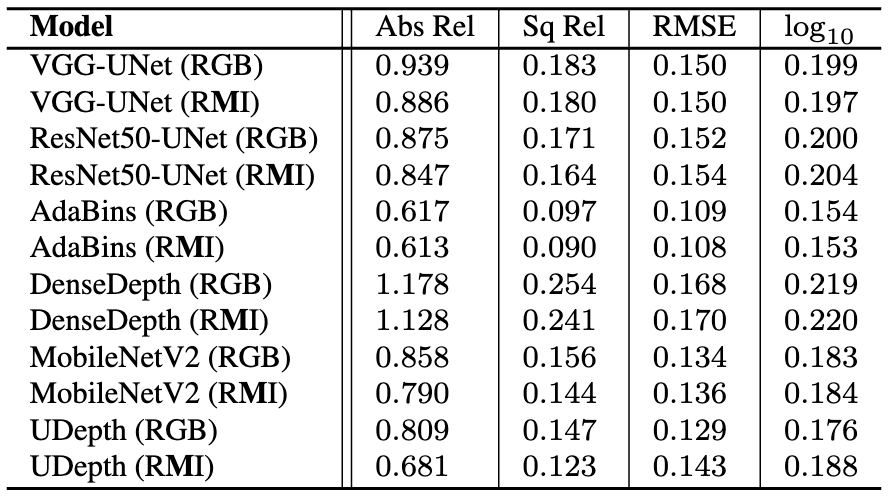
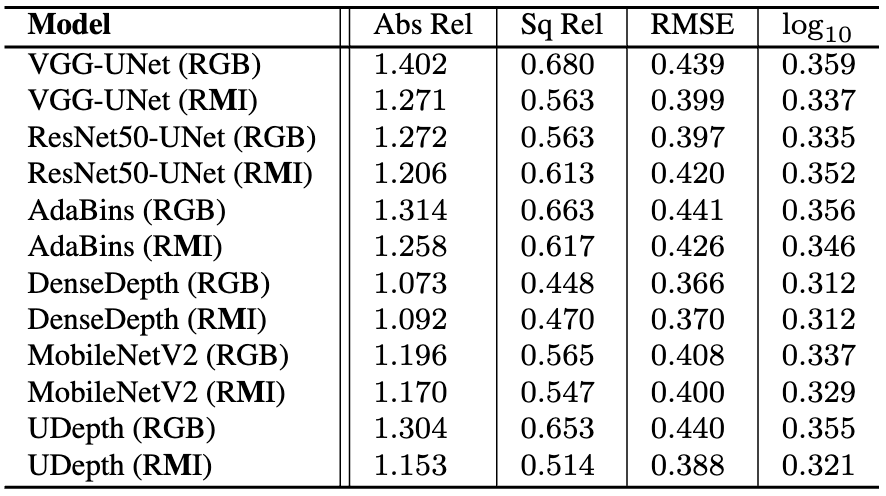
From the quantitative performance, we can observe that:
(i) All models exhibit consistently better results across almost all metrics when trained on the RMI space instead of raw RGB inputs, which validates our contribution to domain-aware input space adaptation.
(ii) The proposed UDepth model outperforms VGG-UNet, ResNetUNet, DesneDepth, and MobileNetV2 regardless of using RMI or RGB input space.
On some metrics, the SOTA model Adabins achieves better scores and generate more accurate visual results.
However, Adabins is a significantly heavier model with 78M+ parameters compared to UDepth, which has only 15.5M parameters.
Hence, our design choices enable UDepth to achieve comparable and often better depth estimation performance than Adabins, despite being over 5× more efficient.
Moreover, UDepth demonstrates much better generalization performance compared to other SOTA models.
Here, we use the D3 (reef) scenes from the Sea-Thru dataset for testing only. While Adabins offers good results, UDepth achieves significantly better results across all metrics on unseen test cases.
In comparison, DenseDepth model shows slightly better performance on unseen underwater images;
however, with 42.6M parameters, it is about 3× computationally heavier.
Quantitative comparison on USOD10K test set
Quantitative performance comparison on Sea-thru (D3) datase
Generalization, Robustness, and Efficiency
We compare the generalization performance of UDepth with its two best competitors: Adabins and DenseDepth on various benchmark datasets.
The output of UDepth are more accurate and consistent with the underwater scene geometry, and it does a particularly better job at removing background regions and predicting foreground layers up to scale.
Moreover, UDepth demonstrates superior performance for background segmentation and depth continuity on unseen natural underwater scenes.
We further compare the computational efficiency of UDepth with Adabins and DenseDepth in the left table.
UDepth is 3-5 times memory efficient and offers 4.4-6.8 times faster inference rates, with over 66 FPS inference on a single GPU (NVIDIA™ RTX 3080) and over 13.5 FPS on CPUs (Intel™ Core i9-3.50GHz).
More importantly, we can extend our domain projection step with guided filtering for fast coarse depth prediction on lowpower embedded devices.
We performed thorough evaluations on field experimental data, which suggest that these abstract predictions are reasonable approximations of natural underwater scene depths.
As shown in the figure below, the filtered domain projections embed useful 3D information about the scenes to facilitate high-level decision-making by visually-guided underwater robots.
The end-to-end domain projection and filtering module generates depth maps at 51.5 FPS rate on NVIDIA™ Jetson TX2s and on 7.92 FPS rate on Raspberry Pi-4s.
Acknowledgments
Field experimental data: Dr. Ioannis Rekleitis, Autonomous Field Robotics Lab (AFRL), Dept of CSE, University of South Carolina
Field trial site: Bellairs Research Institute (BRI) of Barbados